Zig: January 2018 in Review
One month (and a few days, sorry I'm late!) has passed since I did the December 2017 writeup, and so it's time for another month-in-review for my esteemed sponsors.
LLVM 6 Readiness
LLVM 6.0.0rc2 was just announced on the mailing list. It's scheduled to be released on February 21, and Zig is ready. I plan to have Zig release 0.2.0 one week after LLVM 6 comes out. We already have all tests passing with debug builds of LLVM 6 in the llvm6 branch, but that extra week is for a bug-stomping rampage.
After that, all the 0.3.0 milestone issues get postponed to 0.4.0, and all the 0.2.0 milestone issues get moved to 0.3.0.
0.2.0 will be an exciting release because, among many other things, it enables source-level debugging with MSVC on Windows.
Zig is once again in the release notes of LLVM, so we should see a slight increase in community size when LLVM release notes hit the tech news headlines.
Error Syntax Cleanup
One of the biggest complaints newcomers to Zig had was about its sigils regarding error handling. Given this, I made an effort to choose friendlier syntax.
%returnis replaced withtry%deferis replaced witherrdefera %% bis replaced witha catch b%%xis removed entirely to discourage its use. You can get an equivalent effect withx catch unreachable, which has been updated to understand that it was attempting to unwrap an error union. See #545 and #510
After these changes, there is a strong pattern that only keywords can modify control flow.
For example we have and and or instead of && and ||. There is one last exception, which is a ?? b. Maybe it's okay, since C# set a precedent.
An even bigger change is coming soon which I'm calling Error Sets.
Error Return Traces
I'm really excited about this one. I invented a new kind of debugging tool and integrated it into Debug and ReleaseSafe builds.
One of the concerns with removing the %% prefix operator was that it was
just so gosh darn convenient to get a stack trace right at the moment where you
asserted that a value did not have an error. I wanted to make it so that programmers
could use try everywhere and still get the debuggability benefit when
an error occurred.
Watch this:
const std = @import("std");
pub fn main() !void {
const allocator = std.debug.global_allocator;
const args = try std.os.argsAlloc(allocator);
defer std.os.argsFree(allocator, args);
const count = try parseFile(allocator, args[1]);
if (count < 10) return error.NotEnoughItems;
}
fn parseFile(allocator: &std.mem.Allocator, file_path: []const u8) !usize {
const contents = std.io.readFileAlloc(allocator, file_path) catch return error.UnableToReadFile;
defer allocator.free(contents);
return contents.len;
}
Here's a simple program with a bunch of different ways that errors could get returned
from main. In our test example, we're going to open a bogus file that
does not exist.
$ zig build-exe test2.zig
$ ./test2 bogus-does-not-exist.txt
error: UnableToReadFile
/home/andy/dev/zig/build/lib/zig/std/os/index.zig:301:33: 0x000000000021acd0 in ??? (test2)
posix.ENOENT => return PosixOpenError.PathNotFound,
^
/home/andy/dev/zig/build/lib/zig/std/os/file.zig:25:24: 0x00000000002096f6 in ??? (test2)
const fd = try os.posixOpen(allocator, path, flags, 0);
^
/home/andy/dev/zig/build/lib/zig/std/io.zig:267:16: 0x000000000021ebec in ??? (test2)
var file = try File.openRead(allocator, path);
^
/home/andy/dev/zig/build/test2.zig:15:71: 0x000000000021ce72 in ??? (test2)
const contents = std.io.readFileAlloc(allocator, file_path) catch return error.UnableToReadFile;
^
/home/andy/dev/zig/build/test2.zig:9:19: 0x000000000021c1f9 in ??? (test2)
const count = try parseFile(allocator, args[1]);
^
I'm going to include a picture of the above here, because it looks a lot better with terminal colors:
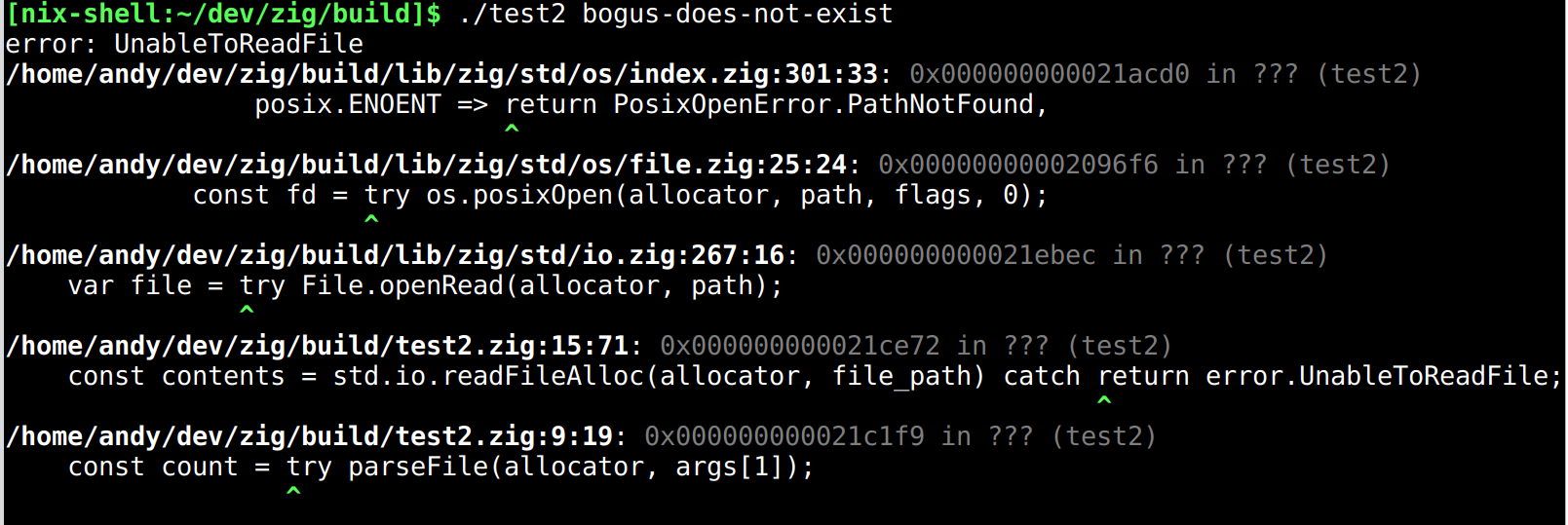
This is not a stack trace snapshot from when an error was "created". This is a return trace of all the points in the code where an error was returned from a function.
Note that, if it only told you the origin of the error that we ultimately received - UnableToReadFile - we would only see the bottom 2 items in the trace.
Not only do we have this information, we have all the information about the origin of
the error, right up to the fact that we received ENOENT from open.
With this in place, programmers can comfortably use try everywhere, safe
in the knowledge that it will be straightforward to troubleshoot the origin of any error
bubbling up through the system.
I hope you're skeptically wondering, OK, what's the tradeoff in terms of binary size, performance, and memory?
First of all, this feature is disabled in ReleaseFast mode. So the answer is, literally no cost, in this case. But what about Debug and ReleaseSafe builds?
To analyze performance cost, there are two cases:
- when no errors are returned
- when returning errors
For the case when no errors are returned, the cost is a single memory write operation, only in the first non-failable function in the call graph that calls a failable function, i.e. when a function returning void calls a function returning error.
This is to initialize this struct in the stack memory:
pub const StackTrace = struct {
index: usize,
instruction_addresses: [N]usize,
};Here, N is the maximum function call depth as determined by call graph analysis. Recursion is ignored and counts for 2.
A pointer to StackTrace is passed as a secret parameter to every function that can return an error, but it's always the first parameter, so it can likely sit in a register and stay there.
That's it for the path when no errors occur. It's practically free in terms of performance.
When generating the code for a function that returns an error, just before the return statement (only for the return statements that return errors), Zig generates a call to this function:
noinline fn __zig_return_error(stack_trace: &StackTrace) void {
stack_trace.instruction_addresses[stack_trace.index] = @returnAddress();
stack_trace.index = (stack_trace.index + 1) % N;
}The cost is 2 math operations plus some memory reads and writes. The memory accessed is constrained and should remain cached for the duration of the error return bubbling.
As for code size cost, 1 function call before a return statement is no big deal. Even so,
I have a plan to make the call to
__zig_return_error a tail call, which brings the code size cost down to actually zero. What is a return statement in code without error return tracing can become a jump instruction in code with error return tracing.
There are a few ways to activate this error return tracing feature:
- Return an error from main
- An error makes its way to
catch unreachableand you have not overridden the default panic handler - Use @errorReturnTrace to access the current return trace. You can use
std.debug.dumpStackTraceto print it. This function returns comptime-knownnullwhen building without error return tracing support.
Documentation
Big news on the documentation front.
All the outdated docs are fixed, and we have automatic docgen tool which:
- Automatically generates the table of contents
- Validates all internal links
- Validates all code examples
- Turns terminal coloring of stack traces and compile errors into HTML
The tool is, of course, written in Zig. #465
In addition to the above, the following improvements were made to the documentation:
- Added documentation for @noInlineCall
- Added documentation for extern enum
- Improved the documentation styling
- Made the documentation a single file that has no external dependencies
- Add the documentation to appveyor build artifacts as
langref.html. In other words we ship with the docs now.
Marc Tiehuis improved documentation styling for mobile devices. #729
- No overscrolling on small screens
- Font-size is reduced for more content per screen
- Tables + Code blocks scroll within a block to avoid page-widenening
There is still much more to document, before we have achieved basic documentation for everything.
Self-Hosted Compiler
The self-hosted compiler now fully successfully builds on Windows and MacOS.
The main test suite builds the self-hosted compiler.
The self-hosted build inherits the std lib file list and C header file list from the stage1 cmake build, as well as the llvm-config output. So if you get stage1 to build,
stage2 will reliably build as well.
Windows 32-bit Support Status
Windows 32-bit mostly works, but there are some failing tests. The number of failing tests grew and it didn't seem fair to claim that we supported it officially.
So I removed the claims that we support Windows 32-bit from the README, and removed 32-bit Windows from the testing matrix.
We still want to support Windows 32-bit.
Syntax: Mandatory Function Return Type
-> is removed, and all functions require an explicit return type.
The purpose of this is:
- Only one way to do things
- Changing a function with void return type to return a possible error becomes a 1 character change, subtly encouraging people to use errors.
Here are some imperfect sed commands for performing this update:
remove arrow:
sed -i 's/\(\bfn\b.*\)-> /\1/g' $(find . -name "*.zig")
add void:
sed -i 's/\(\bfn\b.*\))\s*{/\1) void {/g' $(find . -name "*.zig")
Some cleanup may be necessary, but this should do the bulk of the work.
This has been a controversial change, and may be reverted.
Generating .h Files
- Now Zig emits compile errors for non-extern, non-packed struct, enum, unions in
externfn signatures. - Zig generates .h file content for
externstruct, enum, unions - .h file generation is now tested in the main test suite.
Marc Tiehuis added array type handling:
const Foo = extern struct {
A: [2]i32,
B: [4]&u32,
};
export fn entry(foo: Foo, bar: [3]u8) void { }This generates:
struct Foo {
int32_t A[2];
uint32_t * B[4];
};
TEST_EXPORT void entry(struct Foo foo, uint8_t bar[]);Translating C to Zig
Jimmi Holst Christensen improved translate-c:
- output "undefined" on uninitialized variables
- correct translation of if statements on integers and floats
Crypto Additions to Zig std lib
Marc Tiehuis added a bunch of crypto functions:
Integer Rotation Functions
/// Rotates right. Only unsigned values can be rotated.
/// Negative shift values results in shift modulo the bit count.
pub fn rotr(comptime T: type, x: T, r: var) -> T {
test "math.rotr" {
assert(rotr(u8, 0b00000001, usize(0)) == 0b00000001);
assert(rotr(u8, 0b00000001, usize(9)) == 0b10000000);
assert(rotr(u8, 0b00000001, usize(8)) == 0b00000001);
assert(rotr(u8, 0b00000001, usize(4)) == 0b00010000);
assert(rotr(u8, 0b00000001, isize(-1)) == 0b00000010);
}
/// Rotates left. Only unsigned values can be rotated.
/// Negative shift values results in shift modulo the bit count.
pub fn rotl(comptime T: type, x: T, r: var) -> T {
test "math.rotl" {
assert(rotl(u8, 0b00000001, usize(0)) == 0b00000001);
assert(rotl(u8, 0b00000001, usize(9)) == 0b00000010);
assert(rotl(u8, 0b00000001, usize(8)) == 0b00000001);
assert(rotl(u8, 0b00000001, usize(4)) == 0b00010000);
assert(rotl(u8, 0b00000001, isize(-1)) == 0b10000000);
}MD5 and SHA1 Hash Functions
Some performance comparisons to C.
We take the fastest time measurement taken across multiple runs.
The block hashing functions use the same md5/sha1 methods.
Cpu: Intel(R) Core(TM) i5-6500 CPU @ 3.20GHz
Gcc: 7.2.1 20171224
Clang: 5.0.1
Zig: 0.1.1.304f6f1d
See https://www.nayuki.io/page/fast-md5-hash-implementation-in-x86-assembly:
gcc -O2
661 Mb/s
clang -O2
490 Mb/s
zig --release-fast and zig --release-safe
570 Mb/s
zig
50 Mb/s
See https://www.nayuki.io/page/fast-sha1-hash-implementation-in-x86-assembly :
gcc -O2
588 Mb/s
clang -O2
563 Mb/s
zig --release-fast and zig --release-safe
610 Mb/s
zig
21 Mb/s
In short, zig provides pretty useful tools for writing this sort of code. We are in the lead against clang (which uses the same LLVM backend) with us being slower only against md5 with GCC.
SHA-2 Functions
We take the fastest time measurement taken across multiple runs. Tested across multiple compiler flags and the best chosen.
Cpu: Intel(R) Core(TM) i5-6500 CPU @ 3.20GHz
Gcc: 7.2.1 20171224
Clang: 5.0.1
Zig: 0.1.1.304f6f1d
See https://www.nayuki.io/page/fast-sha2-hashes-in-x86-assembly.
Gcc -O2
219 Mb/s
Clang -O2
213 Mb/s
Zig --release-fast
284 Mb/s
Zig --release-safe
211 Mb/s
Zig
6 Mb/s
Gcc -O2
350 Mb/s
Clang -O2
354 Mb/s
Zig --release-fast
426 Mb/s
Zig --release-safe
300 Mb/s
Zig
11 Mb/s
Blake2 Hash Functions
Blake performance numbers for reference:
Cpu: Intel(R) Core(TM) i5-6500 CPU @ 3.20GHz
-- Blake2s
Zig --release-fast
485 Mb/s
Zig --release-safe
377 Mb/s
Zig
11 Mb/s
-- Blake2b
Zig --release-fast
616 Mb/s
Zig --release-safe
573 Mb/s
Zig
18 Mb/s
Sha3 Hashing Functions
These are on the slower side and could be improved. No performance optimizations yet have been done.
Cpu: Intel(R) Core(TM) i5-6500 CPU @ 3.20GHz
-- Sha3-256
Zig --release-fast
93 Mb/s
Zig --release-safe
99 Mb/s
Zig
4 Mb/s
-- Sha3-512
Zig --release-fast
49 Mb/s
Zig --release-safe
54 Mb/s
Zig
2 Mb/s
Interestingly, release-safe is producing slightly better code than release-fast.
Improvements
- The return type of
maincan now bevoid,noreturn,u8, or an error union. #535 - Implemented bigint div and rem. #405
- Removed coldcc keyword and added @setCold. #661
- Renamed "debug safety" to "runtime safety". #437
- Updated windows build to use llvm 5.0.1. Reported usability issue regarding diaguids.lib to llvm-dev.
- Implemented
std.os.selfExePathandstd.os.selfExeDirPathfor windows. - Added more test coverage.
- The same string literal codegens to the same constant. This makes it so that you can send the same string literal as a comptime slice and get the same type.
Zig now supports structs defined inside a function that reference local constants:
const assert = @import("std").debug.assert;
test "struct inside function" {
const BlockKind = u32;
const Block = struct {
kind: BlockKind,
};
var block = Block { .kind = 1234 };
block.kind += 1;
assert(block.kind == 1235);
}This fixed #672 and #552. However there is still issue #675 which is that structs inside functions get named after the function they are in:
test "struct inside function" {
const Block = struct { kind: u32 };
@compileLog(@typeName(Block));
}When executed gives
| "struct inside function()"
Moving on, Zig now allows enum tag values to not be in parentheses:
const EnumWithTagValues = enum(u4) {
A = 1 << 0,
B = 1 << 1,
C = 1 << 2,
D = 1 << 3,
};Previously this required A = (1 << 0).
Bug Fixes
- fix exp1m implementation by using
@setFloatModeand using modular arithmetic - fix compiler crash related to
@alignOf - fix null debug info for 0-length array type. #702
- fix compiler not able to rename files into place on windows if the file already existed
- fix crash when switching on enum with 1 field and no switch prongs. #712
- fix crash on union-enums with only 1 field. #713
- fix crash when align 1 field before self referential align 8 field as slice return type. #723
- fix error message mentioning
unreachableinstead ofnoreturn - fix std.io.readFileAllocExtra incorrectly returning
error.EndOfStream - workaround for microsoft releasing windows SDK with the wrong version
- Found a bug in NewGVN. Disabled it to match clang and filed an llvm bug.
- emit compile error for @panic called at compile time. #706
- emit compile error for shifting by negative comptime integer. #698
- emit compile error for calling naked function. @ptrCast a naked function first to call it.
- emit compile error for duplicate struct, enum, union fields. #730
Thank you contributors!
- Jimmi Holst Christensen fixed bitrotted code: `std.Rand.scalar` and `std.endian.swap`. (See #674)
- Andrea Orru removed the deprecated Darwin target and added Zen OS target. (See #438)
- Andrea Orru added intrusive linked lists to the standard library. (See #680)
- Jimmi Holst Christensen fixed bigint xor with zero. (See #701)
- Jimmi Holst Christensen implemented windows versions of seekTo and getPos (See #710)
- Jeff Fowler sent a pull request to GitHub/linguist to add Zig syntax highlighting. (See github/linguist/pull/4005)
- Jeff Fowler Added Zig 0.1.1 to Homebrew. (See Homebrew/homebrew-core/pull/23189)
Thank you financial supporters!
Special thanks to those who donate monthly. We're now at $207 of the $3,000 goal.
- Lauren Chavis
- Andrea Orru
- Adrian Sinclair
- David Joseph
- jeff kelley
- Hasen Judy
- Wesley Kelley
- Harry Eakins
- Richard Ohnemus
- Brendon Scheinman
- Martin Schwaighofer
- Matthew
- Mirek Rusin
- Jordan Torbiak
- Pyry Kontio
- Thomas Ballinger
- Peter Ronnquist
- Luke McCarthy
- Robert Paul Herman
- Audun Wilhelmsen
- Marko Mikulicic
- Jimmi Holst Christensen
- Caius
- Don Poor
- Anthony J. Benik
- David Hayden
- Tanner Schultz
- Tyler Philbrick
- Eduard Nicodei
- Christopher A. Butler
- Colleen Silva-Hayden
- Jeremy Larkin
- Rasmus Rønn Nielsen
- Brian Lewis
- Tom Palmer
- Josh McDonald
- Chad Russell
- Alexandra Gillis
- david karapetyan
- Zi He Goh