Statically Recompiling NES Games into Native Executables with LLVM and Go
I have always wanted to write an emulator. I made a half-hearted attempt in college but it never made it to a demo-able state. I also didn't want to write Yet Another Emulator. It should at least bring something new to the table. When I discovered LLVM, I felt like I finally had worthwhile idea for a project.
This article presents original research regarding the possibility of statically disassembling and recompiling Nintendo Entertainment System games into native executables. I attempt to bring the reader along from beginning to end in a sort of "let's build it together" fashion. I assume as little as possible about what the reader knows about the subjects at hand, without compromising the depth of the article.
Table of Contents
- Table of Contents
- Discovering LLVM
- NES Crash Course
- Creating a Custom ABI for Testing Purposes
- Assembly
- Disassembly
- Code Generation
- Optimization
- Layout of an NES ROM File
- Challenge: Runtime Address Checks
- Challenge: Parallel Systems Running Simultaneously
- Challenge: Handling Interrupts
- Challenge: Detecting a Jump Table
- Challenge: Indirect Jumps
- Challenge: Dirty Assembly Tricks
- Video: Playing Super Mario Brothers 1 on Native Machine Code
- Unsolved Challenge: Mappers
- Community Support
- Conclusion
Discovering LLVM
I became giddy with excitement when I discovered LLVM. Generate code in LLVM IR format, and LLVM can optimize and generate native code for any of its supported backends. Here's an incomplete list:
- ARM
- STI CBEA Cell SPU [experimental]
- C++ backend
- Hexagon
- MBlaze
- Mips
- Mips64 [experimental]
- Mips64el [experimental]
- Mipsel
- MSP430 [experimental]
- NVIDIA PTX 32-bit
- NVIDIA PTX 64-bit
- PowerPC 32
- PowerPC 64
- Sparc
- Sparc V9
- Thumb
- 32-bit X86: Pentium-Pro and above
- 64-bit X86: EM64T and AMD64
- XCore
Furthermore, you can write additional backends to support additional targets. For example, emscripten provides a JavaScript backend.
To seal the deal, the LLVM project offers clang, a C, C++, Objective C, and Objective C++ front-end for LLVM. This means that because of the way LLVM is designed, emscripten allows you to compile C, C++, Objective C, and Objective C++ code for the browser. Wow!
Just to show you how refreshing this technology is, have a look at the following C code:
#include <stdio.h>
#include <stdint.h>
int main() {
uint8_t foo = 0xf0;
if (foo & 0x80 == 0x80) {
for (int i = 1; i <= 10; ++i) {
printf("%d\n", i);
}
}
}
Simple enough. Assign 11110000 to foo.
If the highest bit is 1 (which it is), print the integers from 1 to 10.
Compiling with gcc with default settings, we get:
$ gcc test.c test.c: In function ‘main’: test.c:7:5: error: ‘for’ loop initial declarations are only allowed in C99 mode test.c:7:5: note: use option -std=c99 or -std=gnu99 to compile your code $
Right, so default gcc doesn't have the nice things that C99 brings.
Let's try that again with gcc -std=c99:
$ c99 test.c $ ./a.out $
Okay, so now it compiled and ran, but why didn't it print the integers from 1 to 10? Let's try compiling with clang and see what happens:
$ clang test.c
test.c:6:13: warning: & has lower precedence than ==; == will be evaluated
first [-Wparentheses]
if (foo & 0x80 == 0x80) {
^~~~~~~~~~~~~~
test.c:6:13: note: place parentheses around the '==' expression to silence
this warning
if (foo & 0x80 == 0x80) {
^
( )
test.c:6:13: note: place parentheses around the & expression to evaluate it
first
if (foo & 0x80 == 0x80) {
^
( )
1 warning generated.
$
Aha! In C, & has lower precedence than ==. In addition to
outputting with fancy terminal colors, clang found the bug in our program and issued a warning.
Once we fix that up and run the code again, we get the expected behavior.
Note: It has been shown to me that gcc -Wall produces a similar warning
for the same code example here. I apologize for the bogus example. However,
my point still stands.
LLVM has a much better explanation
of the philosophy and differences in error messages between clang and gcc.
There are many instances where cryptic gcc errors in your code are made clear by clang. In the words of my friend Josh Wolfe,
Clang makes gcc look like a rusty old grandpa.
This is exciting because clang is merely a front-end to LLVM. What this means is that if you generate LLVM IR code, you share the same code generation backend as clang. With this I felt that powerful optimization and wide target platform support were within my grasp.
What if we could translate NES assembly code into LLVM IR code? We could completely, statically recompile NES games into native binaries!
NES Crash Course
Take a break from LLVM for a moment and consider the Nintendo Entertainment System.
The NES consists of 4 systems working together in parallel:
- CPU - 8-bit processor. Basically a MOS 6502.
- Picture Processing Unit
- Audio Processing Unit
- Usually a mapper: custom hardware used to provide extra ROM (and sometimes other stuff)
The NES uses memory-mapped I/O, which means that, to interact with hardware, you read from and write to special memory addresses. Take a look at a simplified version of the memory layout of the NES at runtime:
| Start | End | Description |
|---|---|---|
| $0000 | $07ff | RAM. Unless they use a mapper, NES games only get 2KB of RAM! |
| $2000 | $2007 | These memory addresses are hooked up to the PPU and hence are used to control what is being displayed on the screen. |
| $4000 | $4015 | These are hooked up to the APU and are used to control the sound that plays. |
| $4016 | $4017 | These are used to read the state of the game controllers. |
| $8000 | $ffff | This is Read Only Memory. The game code itself is loaded here, so games can embed data in their program code and read it in this address range. |
Let's break this down. First, note that the entire addressable range of the NES is
64KB. Thus all addresses can be represented by 2 bytes, or 4 hex digits. Next,
note that in 6502 assembly, $ is standard for hexadecimal notation.
So the address range is $0000 to $ffff.
Of the 64KB addressable range, 29KB is (usually) completely unused!
Note the $8000 - $ffff range. When you create an NES game, you
write 6502 assembly code, which is assembled into a 32KB binary, which is loaded into the $8000 - $ffff range during bootup.
Let's write some example 6502 code to illustrate.
Creating a Custom ABI for Testing Purposes
One of the challenges of NES development is that a basic "Hello, World" program is pretty complicated. This is why I created a custom Application Binary Interface to make it a little bit easier. Refer back to the memory layout above, and recall that many addresses are unused. I decided to add a couple things:
| Address | Description |
|---|---|
| $2008 | Write a byte to this address and the byte will go to standard out. |
| $2009 | Write a byte to this address and the program will exit with that byte as the return code. |
With this add-on ABI, I was able to create a simple 6502 application that prints
"Hello, World!\n" to stdout and then exits.
In 6502 land, that looks like:
; Remember that this code gets loaded at memory address $8000.
; This instruction tells the assembler that the code and data
; that follow are starting at address $8000.
; For example, the 'W' character in the "Hello, World!\n\0" text
; below is located at memory address $8007.
.org $8000
; This is a label. The assembler will replace references to
; this label with the actual address that it represents, which
; in this case is $8000.
msg:
; 'db' stands for "Data Bytes". This line puts the string
; "Hello, World!\n\0" in bytes $8000 - $800e when this
; code is assembled.
.db "Hello, World!", 10, 0
Reset_Routine:
LDX #$00 ; put the starting index, 0, in register X
loop:
; This instruction does 3 things:
; 1. Take the address of msg and add the value of register X to get a pointer.
; 2. Read the byte at the pointer and put it into register A
; 3. Set the zero flag to 1 if A is zero; or 0 if A is nonzero.
LDA msg, X ; read 1 char
; If the zero flag is 1, goto loopend. Otherwise, go to the next instruction.
BEQ loopend ; end loop if we hit the \0
; Put the value of register A into memory address $2008. But remember,
; with our custom ABI, this means write the value of register A to stdout.
STA $2008 ; putchar
; Register X = Register X + 1
INX
JMP loop ; goto loop
loopend:
LDA #$00 ; put the return code, 0, in register A
STA $2009 ; exit with a return code of register A (0 in this case)
; These are interrupt handlers. Let's not think about interrupts yet.
IRQ_Routine: RTI ; do nothing
NMI_Routine: RTI ; do nothing
; Another org statement. Remember that NES programs are 32KB. This tells the assembler
; to fill the unused space up until $fffa with zeroes and that we are now
; specifying the data at $fffa.
.org $fffa
; 'dw' stands for "Data Words". These lines put the address of the NMI_Routine
; label at $fffa, the address of Reset_Routine at $fffc, and the address
; of IRQ_Routine at $fffe.
.dw NMI_Routine
.dw Reset_Routine
.dw IRQ_Routine
There are some things to point out here. First, note the entry points into the program.
Whereas in most programming environments, there is a main function,
in NES games, the data at $fffa - $ffff has hardcoded special
meaning. When a game starts, the NES reads the 2 bytes at $fffc and
$fffd and uses that as the memory address of the first instruction to run.
Next let's talk about the CPU. In the code snippet above I used register A and register X. There are 6 registers total:
| Name | Bits | Description |
|---|---|---|
| A |
|
The "main" register. Most of the arithmetic operations are performed on this register. |
| X | 8-bit | Another general purpose register. Fewer instructions support X than A. Often used as an index, as in the above code. |
| Y | 8-bit | Pretty much the same as X. Fewer instructions support Y than X. Also often used as an index. |
| P | 8-bit | The "status" register. When the assembly program mentions the "zero flag" it is actually referring to bit 1 (the second smallest bit) of the status register. The other bits mean other things, which we will get into later. |
| SP | 8-bit |
The "stack pointer". The stack is located at $100 - $1ff.
The stack pointer is initialized to $1ff.
When you push a byte on the stack, the stack pointer
is decremented, and when you pull a byte from the stack,
the stack pointer is incremented.
|
| PC |
|
The program counter. You can't directly modify this register but you can indirectly modify it using the stack. |
After coming up with this well-defined task - get "Hello World" running natively - it is time to write some code. First things first - this project should be able to assemble our source code into binary machine code format.
Assembly
One tried and true method to parsing source code is to use a lexer to tokenize the source, and then a parser to turn the tokens into an Abstract Syntax Tree. From there we can process the AST and turn it into the 32KB binary payload.
In Go land, this is straightforward thanks to nex, a lexer, and go tool yacc, a parser that is bundled with Go. Here is the parser code that can build an AST for our "Hello, World" example:
%{
package jamulator
import (
"fmt"
"strconv"
"container/list"
)
// Define the structures that make up the abstract syntax tree.
// Example:
// Label1234:
type LabelStatement struct {
LabelName string
Line int
}
// Example:
// Label1234: BRK
type LabeledStatement struct {
Label *LabelStatement
Stmt interface{}
}
// Example:
// .org $8000
type OrgPseudoOp struct {
Value int
Fill byte
Line int
}
type InstructionType int
const (
// Example:
// ADC #$44
ImmediateInstruction InstructionType = iota
// Example:
// INX
ImpliedInstruction
// Example:
// ADC Label1234, X
DirectWithLabelIndexedInstruction
// Example:
// ADC $44, X
DirectIndexedInstruction
// Example:
// ADC Label1234
DirectWithLabelInstruction
// Example:
// ADC $44
DirectInstruction
// Example:
// ADC ($44, X)
IndirectXInstruction
// Example:
// ADC ($44), Y
IndirectYInstruction
// Example:
// JMP ($81cc)
IndirectInstruction
)
type Instruction struct {
Type InstructionType
OpName string
Line int
// not all fields are used by all instruction types.
Value int
LabelName string
RegisterName string
// filled in later
OpCode byte
Offset int
Payload []byte
}
type DataStmtType int
const (
// Example:
// .db $44
ByteDataStmt DataStmtType = iota
// Example:
// .dw Label1234
WordDataStmt
)
type DataStatement struct {
Type DataStmtType
dataList *list.List
Line int
// filled in later
Offset int
Payload []byte
}
type IntegerDataItem int
type StringDataItem string
type LabelCall struct {
LabelName string
}
type ProgramAst struct {
List *list.List
}
// This is the root node of the abstract syntax tree.
var programAst ProgramAst
%}
// This instructs yacc how to generate a structure that will fit
// any data type that we need to use for a node.
%union {
integer int
str string
list *list.List
orgPsuedoOp *OrgPseudoOp
node interface{}
}
// These are the nodes that we build based on other nodes and tokens.
%type <list> statementList
%type <node> statement
%type <node> instructionStatement
%type <node> dataStatement
%type <list> dataList
%type <list> wordList
%type <node> dataItem
%type <orgPsuedoOp> orgPsuedoOp
%type <node> numberExpr
%type <node> numberExprOptionalPound
// These are tokens that we will encounter when reading the output from
// the lexer.
%token <str> tokIdentifier
%token <integer> tokInteger
%token <str> tokQuotedString
%token tokEqual
%token tokPound
%token tokDot
%token tokComma
%token tokNewline
%token tokDataByte
%token tokDataWord
%token tokProcessor
%token tokLParen
%token tokRParen
%token tokDot
%token tokColon
%token tokOrg
%%
// An assembly program is defined as a statementList.
programAst : statementList {
programAst = ProgramAst{$1}
}
// A statementList is defined as another statementList, plus a single
// statement, or simply as a statement. This creates a linked list
// of statements.
statementList : statementList tokNewline statement {
if $3 == nil {
$$ = $1
} else {
$$ = $1
$$.PushBack($3)
}
} | statement {
if $1 == nil {
$$ = list.New()
} else {
$$ = list.New()
$$.PushBack($1)
}
}
// This defines a statement, which can be many things.
statement : tokDot tokIdentifier instructionStatement {
$$ = &LabeledStatement{
&LabelStatement{"." + $2, parseLineNumber},
$3,
}
} | tokIdentifier tokColon instructionStatement {
$$ = &LabeledStatement{
&LabelStatement{$1, parseLineNumber},
$3,
}
} | orgPsuedoOp {
$$ = $1
} | instructionStatement {
$$ = $1
} | tokDot tokIdentifier dataStatement {
$$ = &LabeledStatement{
&LabelStatement{"." + $2, parseLineNumber},
$3,
}
} | tokIdentifier tokColon dataStatement {
$$ = &LabeledStatement{
&LabelStatement{$1, parseLineNumber},
$3,
}
} | dataStatement {
$$ = $1
} | tokIdentifier tokColon {
$$ = &LabelStatement{$1, parseLineNumber}
} | {
// empty statement
$$ = nil
}
dataStatement : tokDataByte dataList {
$$ = &DataStatement{
Type: ByteDataStmt,
dataList: $2,
Line: parseLineNumber,
}
} | tokDataWord wordList {
$$ = &DataStatement{
Type: WordDataStmt,
dataList: $2,
Line: parseLineNumber,
}
}
wordList : wordList tokComma numberExprOptionalPound {
$$ = $1
$$.PushBack($3)
} | numberExprOptionalPound {
$$ = list.New()
$$.PushBack($1)
}
dataList : dataList tokComma dataItem {
$$ = $1
$$.PushBack($3)
} | dataItem {
$$ = list.New()
$$.PushBack($1)
}
numberExpr : tokPound tokInteger {
tmp := IntegerDataItem($2)
$$ = &tmp
} | tokIdentifier {
$$ = &LabelCall{$1}
}
numberExprOptionalPound : numberExpr {
$$ = $1
} | tokInteger {
tmp := IntegerDataItem($1)
$$ = &tmp
}
dataItem : tokQuotedString {
tmp := StringDataItem($1)
$$ = &tmp
} | numberExprOptionalPound {
$$ = $1
}
orgPsuedoOp : tokOrg tokInteger {
$$ = &OrgPseudoOp{$2, 0xff, parseLineNumber}
} | tokOrg tokInteger tokComma tokInteger {
if $4 > 0xff {
yylex.Error("ORG directive fill parameter must be a single byte.")
}
$$ = &OrgPseudoOp{$2, byte($4), parseLineNumber}
}
instructionStatement : tokIdentifier tokPound tokInteger {
$$ = &Instruction{
Type: ImmediateInstruction,
OpName: $1,
Value: $3,
Line: parseLineNumber,
}
} | tokIdentifier {
$$ = &Instruction{
Type: ImpliedInstruction,
OpName: $1,
Line: parseLineNumber,
}
} | tokIdentifier tokIdentifier tokComma tokIdentifier {
$$ = &Instruction{
Type: DirectWithLabelIndexedInstruction,
OpName: $1,
LabelName: $2,
RegisterName: $4,
Line: parseLineNumber,
}
} | tokIdentifier tokInteger tokComma tokIdentifier {
$$ = &Instruction{
Type: DirectIndexedInstruction,
OpName: $1,
Value: $2,
RegisterName: $4,
Line: parseLineNumber,
}
} | tokIdentifier tokIdentifier {
$$ = &Instruction{
Type: DirectWithLabelInstruction,
OpName: $1,
LabelName: $2,
Line: parseLineNumber,
}
} | tokIdentifier tokInteger {
$$ = &Instruction{
Type: DirectInstruction,
OpName: $1,
Value: $2,
Line: parseLineNumber,
}
} | tokIdentifier tokLParen tokInteger tokComma tokIdentifier tokRParen {
if $5 != "x" && $5 != "X" {
yylex.Error("Register argument must be X.")
}
$$ = &Instruction{
Type: IndirectXInstruction,
OpName: $1,
Value: $3,
Line: parseLineNumber,
}
} | tokIdentifier tokLParen tokInteger tokRParen tokComma tokIdentifier {
if $6 != "y" && $6 != "Y" {
yylex.Error("Register argument must be Y.")
}
$$ = &Instruction{
Type: IndirectYInstruction,
OpName: $1,
Value: $3,
Line: parseLineNumber,
}
} | tokIdentifier tokLParen tokInteger tokRParen {
$$ = &Instruction{
Type: IndirectInstruction,
OpName: $1,
Value: $3,
Line: parseLineNumber,
}
}
%%
And here is the lexer code that generates the tokens listed above:
/\.[dD][bB]/ {
return tokDataByte
}
/\.[dD][wW]/ {
return tokDataWord
}
/\.[oO][rR][gG]/ {
return tokOrg
}
/"[^"\n]*"/ {
t := yylex.Text()
lval.str = t[1:len(t)-1]
return tokQuotedString
}
/[a-zA-Z][a-zA-Z_.0-9]*/ {
lval.str = yylex.Text()
return tokIdentifier
}
/%[01]+/ {
binPart := yylex.Text()[1:]
n, err := strconv.ParseUint(binPart, 2, 16)
if err != nil {
yylex.Error("Invalid binary integer: " + binPart)
}
lval.integer = int(n)
return tokInteger
}
/\$[0-9a-fA-F]+/ {
hexPart := yylex.Text()[1:]
n, err := strconv.ParseUint(hexPart, 16, 16)
if err != nil {
yylex.Error("Invalid hexademical integer: " + hexPart)
}
lval.integer = int(n)
return tokInteger
}
/[0-9]+/ {
n, err := strconv.ParseUint(yylex.Text(), 10, 16)
if err != nil {
yylex.Error("Invalid decimal integer: " + yylex.Text())
}
lval.integer = int(n)
return tokInteger
}
/=/ {
return tokEqual
}
/:/ {
return tokColon
}
/#/ {
return tokPound
}
/\./ {
return tokDot
}
/,/ {
return tokComma
}
/\(/ {
return tokLParen
}
/\)/ {
return tokRParen
}
/[ \t\r]/ {
// ignore whitespace
}
/;[^\n]*\n/ {
// ignore comments
parseLineNumber += 1
return tokNewline
}
/\n+/ {
parseLineNumber += len(yylex.Text())
return tokNewline
}
/./ {
yylex.Error(fmt.Sprintf("Unexpected character: %q", yylex.Text()))
}
//
package jamulator
import (
"strconv"
"os"
"fmt"
)
var parseLineNumber int
var parseFilename string
var parseErrors ParseErrors
type ParseErrors []string
func (errs ParseErrors) Error() string {
return strings.Join(errs, "\n")
}
func Parse(reader io.Reader) (ProgramAst, error) {
parseLineNumber = 1
lexer := NewLexer(reader)
yyParse(lexer)
if len(parseErrors) > 0 {
return ProgramAst{}, parseErrors
}
return programAst, nil
}
func ParseFile(filename string) (ProgramAst, error) {
parseFilename = filename
fd, err := os.Open(filename)
if err != nil { return ProgramAst{}, err }
programAst, err := Parse(fd)
err2 := fd.Close()
if err != nil { return ProgramAst{}, err }
if err2 != nil { return ProgramAst{}, err2 }
return programAst, nil
}
func (yylex Lexer) Error(e string) {
s := fmt.Sprintf("%s line %d %s", parseFilename, parseLineNumber, e)
parseErrors = append(parseErrors, s)
}
Let's demonstrate our ability to parse the source code by printing and inspecting the abstract syntax tree.
import (
"fmt"
"reflect"
"os"
)
func astPrint(indent int, n interface{}) {
for i := 0; i < indent; i++ {
fmt.Print(" ")
}
fmt.Println(reflect.TypeOf(n))
}
func (ast ProgramAst) Print() {
for e := ast.List.Front(); e != nil; e = e.Next() {
astPrint(0, e.Value)
switch t := e.Value.(type) {
case *LabeledStatement:
astPrint(2, t.Label)
astPrint(2, t.Stmt)
case *DataStatement:
for de := t.dataList.Front(); de != nil; de = de.Next() {
astPrint(2, de.Value)
}
}
}
}
func main() {
programAst, err := jamulator.ParseFile("hello.asm")
if err != nil {
fmt.Fprintf(os.Stderr, "%s\n", err.Error())
os.Exit(1)
}
programAst.Print()
}
Now we need to compile this code. At this point, we can no longer rely on Go to build everything because we now have 2 generated Go files:
| Source File | Generated File |
|---|---|
| asm6502.nex | asm6502.nn.go |
| asm6502.y | y.go |
The most straightforward way to build the project at this point is to use a Makefile. Simple enough:
build: jamulator/y.go jamulator/asm6502.nn.go
go build -o jamulate main.go
jamulator/y.go: jamulator/asm6502.y
go tool yacc -o jamulator/y.go -v /dev/null jamulator/asm6502.y
jamulator/asm6502.nn.go: jamulator/asm6502.nex
${GOPATH}/bin/nex -e jamulator/asm6502.nex
clean:
rm -f jamulator/asm6502.nn.go
rm -f jamulator/y.go
rm -f jamulate
.PHONY: build clean
Now we can build the project with one command:
$ make go tool yacc -o jamulator/y.go -v /dev/null jamulator/asm6502.y /home/andy/golang/bin/nex -e jamulator/asm6502.nex go build -o jamulate main.go
And, sure enough, when we run this code, we get a nice breakdown of the source:
$ ./jamulate *jamulator.OrgPseudoOp *jamulator.LabelStatement *jamulator.DataStatement *jamulator.StringDataItem *jamulator.IntegerDataItem *jamulator.IntegerDataItem *jamulator.LabelStatement *jamulator.Instruction *jamulator.LabelStatement *jamulator.Instruction *jamulator.Instruction *jamulator.Instruction *jamulator.Instruction *jamulator.Instruction *jamulator.LabelStatement *jamulator.Instruction *jamulator.Instruction *jamulator.LabeledStatement *jamulator.LabelStatement *jamulator.Instruction *jamulator.LabeledStatement *jamulator.LabelStatement *jamulator.Instruction *jamulator.OrgPseudoOp *jamulator.DataStatement *jamulator.LabelCall *jamulator.DataStatement *jamulator.LabelCall *jamulator.DataStatement *jamulator.LabelCall
Once we have this AST, building a binary is a cinch:
- Loop over the AST and compute the byte offset for each instruction.
- Use the computed byte offsets to resolve the instructions with labels.
- Final pass to write the payload to the disk.
Disassembly
Now we need to work backwards - we have the binary payload and we want to get
the source.
There is a challenge here. Remember that in assembly programs, we can insert
arbitrary data with .db or .dw statements alongside instructions.
In order to disassemble effectively, we have to be able to figure out what
is "data" and what is "code".
One possible technique is to emulate the assembly program, and then record the ways in which memory addresses are accessed. After playing a game for a while, you would have a pretty good record of exactly which sections are data and which are code. I decided not to use this technique, however, since the goal of this project is static recompilation. I want to explore just how much is possible to do at compile-time.
So what can we do?
First, recall that the last 6 bytes in NES programs are 3 memory addresses which are the 3 entry points into the program:
.org $fffa
.dw NMI_Routine
.dw Reset_Routine
.dw IRQ_Routine
Given this, a workable strategy becomes clear:
- Create an AST where every single byte is a single
.dbstatement. -
Replace the
.dbstatements at$fffaand$fffbwith a.dwstatement which references anNMI_Routinelabel. -
Calculate the address that the
.dbstatements at$fffaand$fffbwere referring to, and insert aLabelStatementwith theNMI_Routinelabel before the.dbstatement at that address. -
Mark the
.dbstatement at that address as an instruction.
When I say "mark as an instruction", what I mean is that we should interpret the
.db statement at that location as an op code, and then use that
to replace the following .db statements as part of the instruction
as necessary. Then, based on the instruction, we want to recursively
mark other locations as instructions:
| Instruction | What to Do |
|---|---|
| BPL, BMI, BVC, BVS, BCC, BCS, BNE, BEQ, JSR | Mark the jump target address and the next address as an instruction. |
| JMP absolute | Mark the jump target address as an instruction. |
| RTI, RTS, BRK, JMP indirect | Do nothing. |
| everything else | Mark the next address as an instruction. |
The instructions that start with "B" are all conditional branch instructions. This means that they test some condition, and then either transfer control flow to the next instruction, or to a different label. This means that we can mark the possible branch address and the next address as instructions.
JSR stands for "Jump to SubRoutine". This will transfer control to a
target address and then later when the RTS ("ReTurn from Subroutine")
instruction is reached, continue execution where the JSR instruction left off.
It is possible for assembly programmers to use JSR and then
inside the subroutine, do tricks with the stack to return to a different location.
This is a problem that will be tackled later. It's not an issue with our "Hello World" example.
RTI, RTS, and BRK modify control flow, but the destination
address is not constant, so these instructions do not help us know what else to mark as instructions.
As seen in this table, there are 2 types of JMP instructions: absolute and indirect:
| JMP Type | Example Assembly | Description |
|---|---|---|
| Absolute |
JMP Label_80a2
|
This version is used in the "Hello World" program. It sends control flow to the operand address - which in this example is a label. This version is convenient for disassembly because the destination address is known statically - the address is hard-coded. |
| Indirect |
JMP ($0123)
|
Uses the operand address as a pointer, sending control flow to the address at the pointer. This will prove to be one of the big challenges of this project. More on this later. |
The instructions in the earlier table are the only ones that modify control flow. All other instructions execute serially. Thus if we encounter one of these, we can reliably decode the next byte as an instruction.
Here's what it looks like when we apply this algorithm to our Hello World binary code:
.org $8000
Label_8000:
.db $48
.db $65
.db $6c
.db $6c
.db $6f
.db $2c
.db $20
.db $57
.db $6f
.db $72
.db $6c
.db $64
.db $21
.db $0a
.db $00
Reset_Routine:
LDX #$00
Label_8011:
LDA Label_8000, X
BEQ Label_801d
STA $2008
INX
JMP Label_8011
Label_801d:
LDA #$00
STA $2009
IRQ_Routine:
RTI
NMI_Routine:
RTI
.db $ff
...
(this is repeated about 30,000 times)
...
.db $ff
.dw NMI_Routine
.dw Reset_Routine
.dw IRQ_Routine
This technique was able to decode all of the instructions, but we can't
read the text, and it's pretty annoying having $ff -
the filler byte value - repeated
so many times. Let's add a pass to detect ASCII strings. We can do this
by counting how many characters in a .db statement in a row
are considered "ASCII" and when a threshold of 4 is reached, replace
the .db statements with a quoted string:
.org $8000
Label_8000:
.db "Hello, World!"
.db $0a
.db $00
Reset_Routine:
LDX #$00
Label_8011:
LDA Label_8000, X
BEQ Label_801d
STA $2008
INX
JMP Label_8011
Label_801d:
LDA #$00
STA $2009
IRQ_Routine:
RTI
NMI_Routine:
RTI
.db $ff
.db $ff
...
(repeated about 30,000 times)
...
.db $ff
.db $ff
.dw NMI_Routine
.dw Reset_Routine
.dw IRQ_Routine
Better! Let's solve the problem of the repeating $ff
by adding a pass to detect where it would make sense to place
.org statements. We can do this in much the same way
as ASCII detection, but in this case we will look out for repeating
bytes rather than bytes which fit in the ASCII range. 64 seems
like a good threshold. If a byte repeats 64 times, replace all the
repeated occurences with a .org statement:
.org $8000
Label_8000:
.db "Hello, World!"
.db $0a
.db $00
Reset_Routine:
LDX #$00
Label_8011:
LDA Label_8000, X
BEQ Label_801d
STA $2008
INX
JMP Label_8011
Label_801d:
LDA #$00
STA $2009
IRQ_Routine:
RTI
NMI_Routine:
RTI
.org $fffa
.dw NMI_Routine
.dw Reset_Routine
.dw IRQ_Routine
And finally, one minor detail. Let's do a final pass to collapse .db
statements together:
.org $8000
Label_8000:
.db "Hello, World!", $0a, $00
Reset_Routine:
LDX #$00
Label_8011:
LDA Label_8000, X
BEQ Label_801d
STA $2008
INX
JMP Label_8011
Label_801d:
LDA #$00
STA $2009
IRQ_Routine:
RTI
NMI_Routine:
RTI
.org $fffa
.dw NMI_Routine
.dw Reset_Routine
.dw IRQ_Routine
Not bad. This is as close as we can get to the original source. It's impossible to know what label names were used, but we can give good names to the interrupt vectors. We just turned a binary machine code program into human-readable assembly.
Now that we can figure out the assembly source code from 6502 machine code, we can start the fun part - converting the assembly program into native machine code.
Code Generation
Our code generation code will generate an LLVM bitcode module.
We can then use llc to compile the bitcode into an object file,
the same as if we used gcc -c module.c and looked at the resulting
module.o.
LLVM is written in C++, but it also exposes a C interface. This means we can integrate cleanly using cgo. In fact, Andrew Wilkins maintains a convenient Go module called gollvm which gives us seamless integration.
At any time we can debug the LLVM module we are generating by calling module.Dump()
which prints the LLVM IR code
for the module to stderr. Let's start by manually creating the
IR code that we want to generate for Hello World, so we know what to work toward.
We can get a head start by writing it in C and using clang to generate the IR
code for us:
#include <stdio.h>
char * msg = "Hello, World!\n";
int main() {
char * ptr = msg;
while (*ptr) {
putchar(*ptr);
++ptr;
}
}
$ clang -emit-llvm -S test.c $
Now looking at test.s:
; ModuleID = 'test.c'
target datalayout = "e-p:64:64:64-i1:8:8-i8:8:8-i16:16:16-i32:32:32-i64:64:64-f32:32:32-f64:64:64-v64:64:64-v128:128:128-a0:0:64-s0:64:64-f80:128:128-n8:16:32:64-S128"
target triple = "x86_64-pc-linux-gnu"
@.str = private unnamed_addr constant [15 x i8] c"Hello, World!\0A\00", align 1
@msg = global i8* getelementptr inbounds ([15 x i8]* @.str, i32 0, i32 0), align 8
define i32 @main() nounwind uwtable {
%1 = alloca i32, align 4
%ptr = alloca i8*, align 8
store i32 0, i32* %1
%2 = load i8** @msg, align 8
store i8* %2, i8** %ptr, align 8
br label %3
; <label>:3 ; preds = %7, %0
%4 = load i8** %ptr, align 8
%5 = load i8* %4, align 1
%6 = icmp ne i8 %5, 0
br i1 %6, label %7, label %14
; <label>:7 ; preds = %3
%8 = load i8** %ptr, align 8
%9 = load i8* %8, align 1
%10 = sext i8 %9 to i32
%11 = call i32 @putchar(i32 %10)
%12 = load i8** %ptr, align 8
%13 = getelementptr inbounds i8* %12, i32 1
store i8* %13, i8** %ptr, align 8
br label %3
; <label>:14 ; preds = %3
%15 = load i32* %1
ret i32 %15
}
declare i32 @putchar(i32)
Alright - that looks a bit different than the code we're going to generate, but it's a good start. If that looks complicated, don't worry - we're going to do 3 things to make it less so:
- Read up on the language reference.
- Delete the stuff that seems unnecessary and see if it still works.
- Modify the code to look like what we want to generate.
Here's an updated version with inline comments breaking it down:
; Here we declare the text that we will print.
; "private" means that only this module can see it - we do not export this
; symbol. Always declare private when possible. There are optimizations to be
; had when a symbol is not exported.
; "constant" means that this data is read-only. Again use constant when
; possible so that optimization passes can take advantage of this fact.
; [15 x i8] is the type of this data. i8 means an 8-bit integer.
@msg = private constant [15 x i8] c"Hello, World!\0a\00"
; Here we declare a dependency on the `putchar` symbol.
; When this module is linked, `putchar` must be defined somewhere, and with
; this signature.
declare i32 @putchar(i32)
; Same thing for `exit`.
; `noreturn` indicates that we do not expect this function to return. It will
; end the process, after all.
; `nounwind` has to do with LLVM's error handling model. We use `nounwind`
; because we know that `exit` will not throw an exception.
declare void @exit(i32) noreturn nounwind
; Note that we will be performing the final link step with gcc, which will
; automatically statically link against libc. This will provide the `putchar`
; and `exit` symbols, as well as set up the executable entry point to call `main`.
define i32 @main() {
; This label statement indicates the start of a basic block.
Entry:
; Here we allocate some variables on the stack. These are X, Y, and A,
; 3 of the 6502's 8-bit registers.
%X = alloca i8
%Y = alloca i8
%A = alloca i8
; Note that here we are allocating variables which are single bits.
; These represent 2 of the bits from the status register.
; After this source listing there is a table explaining each bit
; of the status register.
%S_neg = alloca i1
%S_zero = alloca i1
; Send control flow to the Reset_Routine basic block.
br label %Reset_Routine
Reset_Routine:
; This is the code to generate for
; LDX #$00
; Store 0 in the X register.
store i8 0, i8* %X
; Clear the negative status bit, because we just stored 0 in X,
; and 0 is not negative.
store i1 0, i1* %S_neg
; Set the zero status bit, because we just stored 0 in X.
store i1 1, i1* %S_zero
br label %Label_loop
Label_loop:
; This is the code to generate for
; LDA msg, X
; Load the value of X into %0.
%0 = load i8* %X
; Get a pointer to the character in msg indexed by %0, which contains the
; value of X.
%1 = getelementptr [15 x i8]* @msg, i64 0, i8 %0
; Read a byte of memory located at the pointer we just computed into %2.
%2 = load i8* %1
; Store the byte we just loaded into %A, which is the variable we have
; allocated for A.
store i8 %2, i8* %A
; Now we need to set the negative status bit correctly.
; The byte of memory we just loaded into %A is negative if
; and only if the highest bit is set.
; Perform a bitwise AND with 1000 0000.
%3 = and i8 128, %2
; Test if the result is equal to 1000 0000.
%4 = icmp eq i8 128, %3
; Save the answer to the negative status bit.
store i1 %4, i1* %S_neg
; Now we need to set the zero status bit correctly.
; Test if the byte is equal to zero.
%5 = icmp eq i8 0, %2
; Store the answer to the zero status bit.
store i1 %5, i1* %S_zero
; This is the code to generate for
; BEQ loopend
%6 = load i1* %S_zero
; If zero bit is set, go to Label_loopend. Otherwise, go to AutoLabel_0
br i1 %6, label %Label_loopend, label %AutoLabel_0
AutoLabel_0:
; This is the code to generate for
; STA $2008
%7 = load i8* %A
; Convert the 8-bit integer that we just loaded from A into
; a 32-bit integer to match the signature of `putchar`.
%8 = zext i8 %7 to i32
%9 = call i32 @putchar(i32 %8)
br label %AutoLabel_1
AutoLabel_1:
; This is the code to generate for
; INX
%10 = load i8* %X
%11 = add i8 %10, 1
store i8 %11, i8* %X
; Set the negative status bit correctly.
%12 = and i8 128, %11
%13 = icmp eq i8 128, %12
store i1 %13, i1* %S_neg
;Set the zero status bit correctly.
%14 = icmp eq i8 0, %11
store i1 %14, i1* %S_zero
; This is the code to generate for
; JMP loop
br label %Label_loop
Label_loopend:
; This is the code to generate for
; LDA #$00
store i8 0, i8* %A
; Clear the negative status bit.
store i1 0, i1* %S_neg
; Set the zero status bit.
store i1 1, i1* %S_zero
; This is the code to generate for
; STA $2009
%15 = load i8* %A
%16 = zext i8 %15 to i32
call void @exit(i32 %16) noreturn nounwind
; Terminate this basic block with `unreachable` because
; exit never returns.
unreachable
; Generate dummy basic blocks for the
; interrupt vectors, because we don't support them yet.
IRQ_Routine:
unreachable
NMI_Routine:
unreachable
}
In this code we use S_neg and S_zero, 2 of the status register bits.
These bits, along with the other status bits that we did not mention yet,
are updated after certain instructions and used for things such as branching.
Here is a full description of all the status bits:
| Bit Mask | Variable Name | Description |
|---|---|---|
0000 0001
|
S_carry |
Used for arithmetic and bitwise instructions, typically to make it
easier to deal with integers that are larger than 8 bits.
We don't need to deal with this yet.
BCC and BCS use this status bit to decide
whether to branch.
|
0000 0010
|
S_zero |
When a computation results in a value that is equal to zero, this
status bit is set. Otherwise, it is cleared. BEQ and
BNE use this status bit to decide whether to branch.
|
0000 0100
|
S_int |
This bit indicates whether interrupts are disabled. You can use SEI
to set this bit, and CLI to clear this bit. More on interrupts later.
|
0000 1000
|
S_dec |
Normally, this bit would toggle decimal mode on and off.
However, the NES disables this feature of the CPU, so it effectively
does nothing. You can use SED to set this bit, and
CLD to clear this bit.
|
0001 0000
|
S_brk |
This bit is set when a BRK instruction has been executed and an
interupt has been generated to process it.
We'll ignore this bit for now.
|
0010 0000
|
- | This bit is unused. It remains 0 at all times. |
0100 0000
|
S_over |
When a computation results in an invalid
two's complement
value, this bit is set.
Otherwise, it is cleared.
BVC and BVS use this to decide whether to branch.
|
1000 0000
|
S_neg |
When a computation results in a negative two's complement value, this bit is set.
Otherwise, it is cleared. BPL and BMI use this status
bit to decide whether to branch.
|
Let's make sure our goal LLVM code does what we expect:
$ llc -filetype=obj hello.llvm $ gcc hello.llvm.o $ ./a.out Hello, World! $
llc converts the LLVM IR code into a native object file, and then
gcc does the final link step, statically linking against libc
to hook up main, putchar, and exit.
By default, gcc creates an executable named a.out,
which we run, and viola!
The next step is to generate this code from our disassembly. With the help of gollvm we will:
- Create a LLVM module.
- Declare our dependency on
putcharandexit. -
Create the
mainfunction and allocate stack variables for the registers. - Perform one pass over the AST to identify labeled data and create global variables. We save the index of label name to global variable in a map.
- Perform a second pass over the AST to generate the basic blocks and save an index of label name to basic block in a map.
- Final pass over the AST to generate code inside of the basic blocks.
Here is a structure that contains the state we need while compiling:
type Compilation struct {
// Keep track of the warnings and errors
// that occur while compiling.
Warnings []string
Errors []string
// program is our abstract syntax tree -
// we will make several passes over it during
// the compilation process.
program *Program
// LLVM variable which represents the module we
// are creating.
mod llvm.Module
// This is the object that we will use to do all the
// code generation. It's used to create every kind
// of statement.
builder llvm.Builder
// Reference to our main function.
mainFn llvm.Value
// References to the functions we declared, so we
// can call them.
putCharFn llvm.Value
exitFn llvm.Value
// References to the variables we allocate on the stack
// so we can use them in instructions.
rX llvm.Value
rY llvm.Value
rA llvm.Value
rSNeg llvm.Value
rSZero llvm.Value
// Maps label name to the global variables that we add,
// for when the code loads data from a label.
labeledData map[string]llvm.Value
// Maps label name to basic block, so that when
// code branches to another label, we can branch to
// the relevant basic block.
labeledBlocks map[string]llvm.BasicBlock
// Keeps track of the basic block we are currently
// generating code for, if any.
currentBlock *llvm.BasicBlock
// Keeps a reference to the reset routine basic block
// so we know where to first jump to from the entry point.
resetBlock *llvm.BasicBlock
}
With this structure, we can execute our plan:
func (p *Program) Compile(filename string) (c *Compilation) {
llvm.InitializeNativeTarget()
c = new(Compilation)
c.program = p
c.Warnings = []string{}
c.Errors = []string{}
c.mod = llvm.NewModule("asm_module")
c.builder = llvm.NewBuilder()
defer c.builder.Dispose()
c.labeledData = map[string]llvm.Value{}
c.labeledBlocks = map[string]llvm.BasicBlock{}
// First pass to identify labeled data and create
// global variables, saving the indexes in `c.labeledData`.
c.identifyLabeledDataPass()
// declare i32 @putchar(i32)
i32Type := llvm.Int32Type()
putCharType := llvm.FunctionType(i32Type, []llvm.Type{i32Type}, false)
c.putCharFn = llvm.AddFunction(c.mod, "putchar", putCharType)
c.putCharFn.SetLinkage(llvm.ExternalLinkage)
// declare void @exit(i32) noreturn nounwind
exitType := llvm.FunctionType(llvm.VoidType(), []llvm.Type{i32Type}, false)
c.exitFn = llvm.AddFunction(c.mod, "exit", exitType)
c.exitFn.AddFunctionAttr(llvm.NoReturnAttribute | llvm.NoUnwindAttribute)
c.exitFn.SetLinkage(llvm.ExternalLinkage)
// main function / entry point
mainType := llvm.FunctionType(i32Type, []llvm.Type{}, false)
c.mainFn = llvm.AddFunction(c.mod, "main", mainType)
c.mainFn.SetFunctionCallConv(llvm.CCallConv)
entry := llvm.AddBasicBlock(c.mainFn, "Entry")
c.builder.SetInsertPointAtEnd(entry)
c.rX = c.builder.CreateAlloca(llvm.Int8Type(), "X")
c.rY = c.builder.CreateAlloca(llvm.Int8Type(), "Y")
c.rA = c.builder.CreateAlloca(llvm.Int8Type(), "A")
c.rSNeg = c.builder.CreateAlloca(llvm.Int1Type(), "S_neg")
c.rSZero = c.builder.CreateAlloca(llvm.Int1Type(), "S_zero")
// Second pass to build basic blocks.
c.buildBasicBlocksPass()
// Finally, one last pass for codegen.
c.codeGenPass()
// hook up the first entry block to the reset block
c.builder.SetInsertPointAtEnd(entry)
c.builder.CreateBr(*c.resetBlock)
err := llvm.VerifyModule(c.mod, llvm.ReturnStatusAction)
if err != nil {
c.Errors = append(c.Errors, err.Error())
return
}
// Uncomment this to print the LLVM IR code we just generated
// to stderr.
//c.mod.Dump()
fd, err := os.Create(filename)
if err != nil {
c.Errors = append(c.Errors, err.Error())
return
}
err = llvm.WriteBitcodeToFile(c.mod, fd)
if err != nil {
c.Errors = append(c.Errors, err.Error())
return
}
err = fd.Close()
if err != nil {
c.Errors = append(c.Errors, err.Error())
return
}
}
Here's what it the module looks like after only the first pass which identifies labeled data:
; ModuleID = 'asm_module'
@Label_c000 = private global [15 x i8] c"Hello, World!\0A\00"
That's it. All we've done is created a global variable for msg
(which is known as Label_c000 in our disassembly) and saved it in
the c.labeledData map.
Now add in the declares and main function definition, and we get:
; ModuleID = 'asm_module'
@Label_c000 = private global [15 x i8] c"Hello, World!\0A\00"
declare i32 @putchar(i32)
declare void @exit(i32) noreturn nounwind
define i32 @main() {
Entry:
%X = alloca i8
%Y = alloca i8
%A = alloca i8
%S_neg = alloca i1
%S_zero = alloca i1
}
Nothing fancy here. Next let's add in the second pass to identify basic blocks:
; ModuleID = 'asm_module'
@Label_c000 = private global [15 x i8] c"Hello, World!\0A\00"
declare i32 @putchar(i32)
declare void @exit(i32) noreturn nounwind
define i32 @main() {
Entry:
%X = alloca i8
%Y = alloca i8
%A = alloca i8
%S_neg = alloca i1
%S_zero = alloca i1
Reset_Routine: ; No predecessors!
Label_c011: ; No predecessors!
Label_c01d: ; No predecessors!
IRQ_Routine: ; No predecessors!
NMI_Routine: ; No predecessors!
}
At this point we've created basic blocks for each of our labels and saved them
in our c.labeledBlocks map.
And finally, we do the actual code generation pass and add the jump from the entry block to the reset block.
The actual code generation code is surprisingly simple. It consists of a switch case, and a few calls into the llvm builder object. For example, here's the code generation code for LDX #$00:
func (i *Instruction) Compile(c *Compilation) {
v := llvm.ConstInt(llvm.Int8Type(), uint64(i.Value), false)
switch i.OpCode {
case 0xa2: // ldx
c.builder.CreateStore(v, c.rX)
c.testAndSetZero(i.Value)
c.testAndSetNeg(i.Value)
// more cases for other immediate instructions
}
}
func (c *Compilation) testAndSetZero(v int) {
if v == 0 {
c.setZero()
return
}
c.clearZero()
}
func (c *Compilation) setZero() {
c.builder.CreateStore(llvm.ConstInt(llvm.Int1Type(), 1, false), c.rSZero)
}
func (c *Compilation) clearZero() {
c.builder.CreateStore(llvm.ConstInt(llvm.Int1Type(), 0, false), c.rSZero)
}
func (c *Compilation) testAndSetNeg(v int) {
if v&0x80 == 0x80 {
c.setNeg()
return
}
c.clearNeg()
}
func (c *Compilation) setNeg() {
c.builder.CreateStore(llvm.ConstInt(llvm.Int1Type(), 1, false), c.rSNeg)
}
func (c *Compilation) clearNeg() {
c.builder.CreateStore(llvm.ConstInt(llvm.Int1Type(), 0, false), c.rSNeg)
}
For completeness's sake, let's look at one more code gen example. Here's the code generation code for LDA msg, X:
func (i *Instruction) Compile(c *Compilation) {
switch i.OpCode {
case 0xbd: // LDA label, X
// Look up the global module variable based on the label name.
dataPtr := c.labeledData[i.LabelName]
index := c.builder.CreateLoad(c.rX, "")
// This is what we index into the global variable with.
indexes := []llvm.Value{
llvm.ConstInt(llvm.Int8Type(), 0, false),
index,
}
// Obtain a pointer to the element that we want to load.
ptr := c.builder.CreateGEP(dataPtr, indexes, "")
v := c.builder.CreateLoad(ptr, "")
c.builder.CreateStore(v, c.rA)
c.dynTestAndSetNeg(v)
c.dynTestAndSetZero(v)
// more cases for other direct-with-label-indexed instructions
}
}
func (c *Compilation) dynTestAndSetNeg(v llvm.Value) {
x80 := llvm.ConstInt(llvm.Int8Type(), uint64(0x80), false)
masked := c.builder.CreateAnd(v, x80, "")
isNeg := c.builder.CreateICmp(llvm.IntEQ, masked, x80, "")
c.builder.CreateStore(isNeg, c.rSNeg)
}
func (c *Compilation) dynTestAndSetZero(v llvm.Value) {
zeroConst := llvm.ConstInt(llvm.Int8Type(), uint64(0), false)
isZero := c.builder.CreateICmp(llvm.IntEQ, v, zeroConst, "")
c.builder.CreateStore(isZero, c.rSZero)
}
After implementing codegen for the rest of the instructions, here is the module dump after the code generation pass:
; ModuleID = 'asm_module'
@Label_c000 = private global [15 x i8] c"Hello, World!\0A\00"
declare i32 @putchar(i32)
declare void @exit(i32) noreturn nounwind
define i32 @main() {
Entry:
%X = alloca i8
%Y = alloca i8
%A = alloca i8
%S_neg = alloca i1
%S_zero = alloca i1
br label %Reset_Routine
Reset_Routine: ; preds = %Entry
store i8 0, i8* %X
store i1 true, i1* %S_zero
store i1 false, i1* %S_neg
br label %Label_c011
Label_c011: ; preds = %else, %Reset_Routine
%0 = load i8* %X
%1 = getelementptr [15 x i8]* @Label_c000, i8 0, i8 %0
%2 = load i8* %1
store i8 %2, i8* %A
%3 = and i8 %2, -128
%4 = icmp eq i8 %3, -128
store i1 %4, i1* %S_neg
%5 = icmp eq i8 %2, 0
store i1 %5, i1* %S_zero
%6 = load i1* %S_zero
br i1 %6, label %Label_c01d, label %else
else: ; preds = %Label_c011
%7 = load i8* %A
%8 = zext i8 %7 to i32
%9 = call i32 @putchar(i32 %8)
%10 = load i8* %X
%11 = add i8 %10, 1
store i8 %11, i8* %X
%12 = and i8 %11, -128
%13 = icmp eq i8 %12, -128
store i1 %13, i1* %S_neg
%14 = icmp eq i8 %11, 0
store i1 %14, i1* %S_zero
br label %Label_c011
Label_c01d: ; preds = %Label_c011
store i8 0, i8* %A
store i1 true, i1* %S_zero
store i1 false, i1* %S_neg
%15 = load i8* %A
%16 = zext i8 %15 to i32
call void @exit(i32 %16)
unreachable
IRQ_Routine: ; preds = %Label_c01d
unreachable
NMI_Routine: ; No predecessors!
unreachable
}
Great! This looks just like the code we wanted to get, minus the comments and with a few things renamed. Let's make sure it runs as expected:
$ llc -filetype=obj hello.bc $ gcc hello.bc.o $ ./a.out Hello, World! $
At this point in the project we are able to recompile a simple "Hello, World" 6502 program with a small custom ABI into native machine code and then execute it.
Optimization
Did you notice that we never used the value of S_neg?
We only ever stored it.
This is a waste of CPU cycles. We can do better. However, we don't want to
completely remove the ability to compute S_neg -
although this "Hello World" example does
not use the value, other code might.
Optimization is an enormously complicated topic, with its own well-deserved field. Luckly, we won't have to wrap our heads around it in order to benefit. LLVM IR code is designed to be optimized. LLVM comes with state of the art optimization techniques, in the form of passes that you run on a module.
Let's run several optimization passes on the module we generate before rendering bitcode:
| Optimization Name | Description |
|---|---|
| Constant Propagation | Looks for instructions involving only constants and replaces them with a constant value instead of an instruction. |
| Combine Redundant Instructions | Combines instructions to form fewer, simple instructions. For example if you add 1 twice, it will instead add 2. |
| Promote Memory to Register | This pass allows us to load every "register" variable (X, Y, A, etc) before performing an instruction, and then store the register variable back after performing the instruction. This optimization pass will convert our allocated variables into registers, eliminating all the redundancy. |
| Global Value Numbering | Eliminates partially and fully redundant instructions, and delete redundant load instructions. |
| Control Flow Graph Simplification | Removes unnecessary code and merges basic blocks together when possible. |
Here's what it looks like to add these optimization passes to our
Compile code:
// ...
err := llvm.VerifyModule(c.mod, llvm.ReturnStatusAction)
if err != nil {
c.Errors = append(c.Errors, err.Error())
return
}
// This creates an engine object which has useful information
// about our machine as a target.
engine, err := llvm.NewJITCompiler(c.mod, 3)
if err != nil {
c.Errors = append(c.Errors, err.Error())
return
}
defer engine.Dispose()
pass := llvm.NewPassManager()
defer pass.Dispose()
pass.Add(engine.TargetData())
pass.AddConstantPropagationPass()
pass.AddInstructionCombiningPass()
pass.AddPromoteMemoryToRegisterPass()
pass.AddGVNPass()
pass.AddCFGSimplificationPass()
pass.Run(c.mod)
// Uncomment this to print the LLVM IR code we just generated
// to stderr.
//c.mod.Dump()
// ...
LLVM offers many more available passes, and it's up to the user to choose which ones, and in which order, to run. Let's see how the ones chosen in the table above perform on our "Hello World" code:
; ModuleID = 'asm_module'
@Label_c000 = private global [15 x i8] c"Hello, World!\0A\00"
declare i32 @putchar(i32)
declare void @exit(i32) noreturn nounwind
define i32 @main() {
Entry:
br label %Label_c011
Label_c011: ; preds = %else, %Entry
%storemerge = phi i8 [ 0, %Entry ], [ %6, %else ]
%0 = sext i8 %storemerge to i64
%1 = getelementptr [15 x i8]* @Label_c000, i64 0, i64 %0
%2 = load i8* %1, align 1
%3 = icmp eq i8 %2, 0
br i1 %3, label %Label_c01d, label %else
else: ; preds = %Label_c011
%4 = zext i8 %2 to i32
%5 = call i32 @putchar(i32 %4)
%6 = add i8 %storemerge, 1
br label %Label_c011
Label_c01d: ; preds = %Label_c011
call void @exit(i32 0)
unreachable
}
Wow! The code looks completely different, and much simpler. But does it still run?
$ llc -filetype=obj hello.bc $ gcc hello.bc.o $ ./a.out Hello, World! $
Sure does!
Now, not only are we recompiling a simple 6502 program for native machine code, but we're actually generating highly optimized code. But it's not time to congratulate ourselves yet. This is a contrived case. Let's see if these techniques can work on an actual NES game.
Layout of an NES ROM File
The generally accepted standard for distributing NES games is the .nes format, originally started by the iNES emulator. A .nes file looks like:
- 16 byte header with metadata, such as:
- What mapper, if any, the game uses.
- Whether the PPU uses vertical or horizontal mirroring. For now, don't worry so much about exactly what this means, as much as that it is a setting that the PPU needs to know about at bootup.
- The 32 KB of assembled code which gets loaded into $8000 - $ffff on bootup. If there is a mapper, there might be more of this program data, but we'll talk about that later.
- 8KB of graphics data, known as CHR-ROM. This gets loaded into the PPU on bootup. Again if there is a mapper, there might be more of this graphics data.
If you're looking for a reference for the gory details of this format, see the Nesdev Wiki or the official specification.
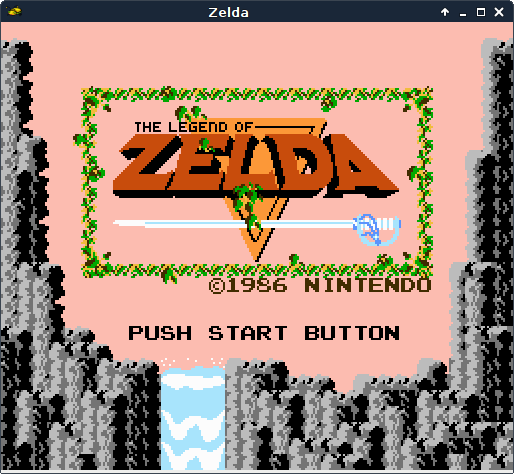
The first "real" ROM I tried to recompile is this demo ROM made by Chris Covell in 1998 called Zelda Title Screen Simulator. If you run this ROM in an emulator, you get a title screen that looks nearly identical to Zelda 1:
Now that we're recompiling a real ROM, we'll have to do several more things to make it work:
- Include the graphics data in the binary.
- Include the mirroring setting (vertical or horizontal) in the binary.
- Support code gen for more instructions.
- Include a runtime to create a window and render the video to the screen.
Including the graphics data and mirroring setting in the binary is trivial. We get all the information we need when we read the ROM file; all we need to do is convert it to global variables in our LLVM module:
// In this snippet, `program` is an object which contains
// the information we loaded from the ROM file.
// chrRom is [][]byte - n banks of 8KB. At this point,
// we only support 1 bank.
if len(program.chrRom) != 1 {
panic("Only 1 bank of CHR ROM is supported.")
}
dataLen := 0x2000 * len(chrRom)
chrDataValues := make([]llvm.Value, 0, dataLen)
int8type := llvm.Int8Type()
for _, bank := range chrRom {
for _, b := range bank {
chrDataValues = append(chrDataValues, llvm.ConstInt(int8type, uint64(b), false))
}
}
chrDataConst := llvm.ConstArray(llvm.ArrayType(llvm.Int8Type(), dataLen), chrDataValues)
// `c.mod` is our `llvm.Module` object. `c` is an instance of our
// `Compilation` struct from a previous code listing.
chrDataGlobal := llvm.AddGlobal(c.mod, chrDataConst.Type(), "rom_chr_data")
// Setting the linkage to private here. We'll figure out what to do
// with this information soon.
chrDataGlobal.SetLinkage(llvm.PrivateLinkage)
chrDataGlobal.SetInitializer(chrDataConst)
chrDataGlobal.SetGlobalConstant(true)
// Now we add the global variable specifying the mirroring setting.
mirroringValue := llvm.ConstInt(llvm.Int8Type(), uint64(program.Mirroring), false)
mirroringGlobal := llvm.AddGlobal(c.mod, mirroringValue.Type(), "rom_mirroring")
mirroringGlobal.SetLinkage(llvm.PrivateLinkage)
mirroringGlobal.SetInitializer(mirroringValue)
mirroringGlobal.SetGlobalConstant(true)
The next step to getting our selected ROM to work is to support the additional instructions that this program uses. Let's unpack that rom and see what we're up against:
$ ./jamulate -unrom roms/Zelda.NES loading roms/Zelda.NES disassembling to roms/Zelda $ ls -l roms/Zelda -rw-rw-r-- 1 andy andy 8192 May 24 23:53 chr0.chr -rw-rw-r-- 1 andy andy 7977 May 24 23:53 prg.asm -rw-rw-r-- 1 andy andy 485 May 24 23:53 Zelda.jam
The code to unpack a .nes file into CHR data, PRG data, and metadata is left as an exercise to the reader.
chr0.chr is binary data; it is the 8KB of graphics data mentioned
before which is loaded into the PPU on bootup.
Zelda.jam is where I decided to put the program metadata
in a simple key-value text format:
# output file name when this rom is assembled
filename=Zelda.NES
# see http://wiki.nesdev.com/w/index.php/Mapper
mapper=0
# 'Horizontal', 'Vertical', or 'FourScreenVRAM'
# see http://wiki.nesdev.com/w/index.php/Mirroring
mirroring=Horizontal
# whether SRAM in CPU $6000-$7FFF is present
sram=true
# whether the SRAM in CPU $6000-$7FFF, if present, is battery backed
battery=false
# 'NTSC', 'PAL', or 'DualCompatible'
tvsystem=NTSC
# assembly code
prg=prg.asm
# video data
chr=chr0.chr
In retrospect, I think it would have been simpler to have the assembler support special declarations for this metadata rather than having a separate file. But hey, it works.
You may notice there is some metadata there which is never addressed in this article. For the purposes of this project, we don't need to think about SRAM, battery, or tvsystem. None of the examples we look at use them.
Without further ado, let's see how the disassembler fared:
.org $c000
.db "Zelda Simulator, ", $a9, "1998 Chris Covell (ccovell@direct.ca)"
Reset_Routine:
CLD
SEI
Label_c039:
LDA $2002
BPL Label_c039
LDX #$00
STX $2000
STX $2001
DEX
TXS
LDY #$06
STY $01
LDY #$00
STY $00
LDA #$00
Label_c052:
STA ($00), Y
DEY
BNE Label_c052
DEC $01
BPL Label_c052
LDX #$3f
STX $2006
LDX #$00
STX $2006
LDX #$27
LDY #$20
Label_c069:
STX $2007
DEY
BNE Label_c069
LDX #$3f
STX $2006
LDX #$00
STX $2006
LDX #$00
LDY #$20
Label_c07d:
LDA Label_c101, X
STA $2007
INX
DEY
BNE Label_c07d
LDX #$23
STX $2006
LDX #$c0
STX $2006
LDX #$00
LDY #$40
Label_c095:
LDA Label_c121, X
STA $2007
INX
DEY
BNE Label_c095
LDX #$20
STX $2006
LDX #$00
STX $2006
LDX #$00
LDY #$00
Label_c0ad:
LDA Label_c261, X
STA $2007
INX
DEY
BNE Label_c0ad
LDX #$00
LDY #$00
Label_c0bb:
LDA Label_c361, X
STA $2007
INX
DEY
BNE Label_c0bb
LDX #$00
LDY #$00
Label_c0c9:
LDA Label_c461, X
STA $2007
INX
DEY
BNE Label_c0c9
LDX #$00
LDY #$c0
Label_c0d7:
LDA Label_c561, X
STA $2007
INX
DEY
BNE Label_c0d7
LDX #$00
STX $2003
LDX #$00
LDY #$00
Label_c0ea:
LDA Label_c161, X
STA $2004
INX
DEY
BNE Label_c0ea
LDA #$90
STA $2000
LDA #$1e
STA $2001
Label_c0fe:
JMP Label_c0fe
Label_c101:
.db $36, $0d, $00, $10, $36, $17, $27, $0d
.db $36, $08, $1a, $28, $36, $30, $31, $22
.db $36, $30, $31, $11, $36, $15, $15, $15
.db $36, $08, $1a, $28, $36, $30, $31, $22
Label_c121:
.db $05, $05, $05, $05, $05, $05, $05, $05
.db $08, "jZZZZ", $9a, $22, $00, "fUUUU", $99, $00
.db $00, $6e, $5f, $55, $5d, $df, $bb, $00
.db $00, $0a, $0a, $0a, $0a, $0a, $0a, $00
.db $00, $00, $c0, $30, $00, $00, $00, $00
.db $00, $00, $cc, $33, $00, $00, $00, $00
.db $00, $20, $fc, $f3, $00, $00, $f0, $f0
Label_c161:
.db $27, $ca, $02, $28, $2f, $cb, $02, $28
.db $27, $cc, $02, $30, $2f, $cd, $02, $30
.db $27, $d6, $02, $50, $2c, $d6, $02, $a0
.db $27, $cc, $42, $c8, $2f, $cd, $42, $c8
.db $27, $ca, $42, $d0, $2f, $cb, $42, $d0
.db $31, $d2, $02, $57, $31, $d4, $02, $5f
.db $3f, $d4, $02, $24, $41, $d4, $02, $63
.db $4f, $d6, $02, $2c, $4f, $d2, $02, $cb
.db $57, $ce, $02, $73, $5f, $cf, $02, $73
.db $57, $d0, $02, $7b, $5f, $d1, $02, $7b
.db $67, $d2, $02, $7a, $7b, $d4, $02, $90
.db $7b, $d6, $02, $bc, $82, $d2, $02, $50
.db $77, $cb, $82, $28, $7f, $ca, $82, $28
.db $77, $cd, $82, $30, $7f, $cc, $82, $30
.db $77, $cd, $c2, $c8, $7f, $cc, $c2, $c8
.db $77, $cb, $c2, $d0, $7f, $ca, $c2, $d0
.db $af, $a3, $00, $50, $af, $a5, $00, $58
.db $af, $a7, $00, $60, $af, $a9, $00, $68
.db $b7, $b2, $00, $50, $b7, $b4, $00, $58
.db $b7, $b6, $00, $60, $b7, $b8, $00, $68
.db $c9, $c2, $00, $50, $d1, $c3, $00, $50
.db $c9, $c4, $00, $58, $d1, $c5, $00, $58
.db $c9, $c6, $00, $60, $d1, $c7, $00, $60
.db $c9, $c8, $00, $68, $d1, $c9, $00, $68
.db $d9, $c2, $00, $50, $e1, $c3, $00, $50
.db $d9, $c4, $00, $58, $e1, $c5, $00, $58
.db $d9, $c6, $00, $60, $e1, $c7, $00, $60
.db $d9, $c8, $00, $68, $e1, $c9, $00, $68
.db $67, $a0, $03, $58, $67, $a0, $03, $60
.db $67, $a0, $03, $68, $67, $a0, $03, $70
.db $67, $a0, $03, $78, $67, $a0, $03, $80
.db $67, $a0, $03, $88, $00, $b0, $00, $00
Label_c261:
.db "$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$", $e0, $d5, "$$$$$$$$$$$$$$$$$$$$$$$$$$$$", $d4, $e0, $dc, $d7
.db "$$$$$$$$$$$$$$$$$$$$$$$$$$$$", $d6, $dd, $dc, $ee, "$$$$$$$$$$$$$$$$$$$$$$$$$$$$", $d6, $db
.db $de, $d7, $24, $24, $24, $e6, $e4, $e5
.db $e4, $e5, $e4, $e5, $e4, $e5, $e4, $e5
.db $e4, $e5, $e4, $e5, $e4, $e5, $e4, $e5
.db $e4, $e5, $e6, $24, $24, $24, $d6, $db
.db $dc, $d7, $24, $24, $24, $e2, "$$$$$$$$$$$$$$$$$$$$", $e3
.db $24, $24, $24, $d6, $df, $de, $ee, $24
.db $24, $24, $e3, "$$qrstuvwxyyyz{$$$$$", $e2, $24, $24, $24
.db $d6, $db
Label_c361:
.db $de, $d8, $ef, $24, $24, $e2, $24, $7c
.db $7d, $7e, $7f, $80, $81, $82, $83, $84
.db $85, $86, $87, $88, $89, $8a, $8b, $24
.db $24, $24, $e3, $24, $24, $24, $d6, $df
.db $dc, $da, $d7, $24, $24, $e3, $24, $8c
.db $8d, $8e, $8f, $90, $91, $92, $93, $94
.db $95, $96, $97, $98, $99, $9a, $9b, $9c
.db $24, $24, $e2, $24, $24, $d4, $d9, $db
.db $dc, $d9, $ee, $24, $24, $e2, $24, $9d
.db $9e, $9f, $a0, $a1, $a2, $a3, $a4, $a5
.db $a6, $a7, $a8, $a9, $aa, $ab, $ac, $ad
.db $ae, $24, $e3, $24, $24, $d6, $db, $df
.db $de, $db, $d7, $24, $24, $e3, $70, $af
.db $b0, $b1, $b2, $b3, $b4, $b5, $b6, $b7
.db $b8, $b9, $ba, $bb, $bc, $bd, $be, $bf
.db $c0, $24, $e2, $24, $24, $d6, $db, $db
.db $dc, $dd, $d7, $24, $24, $e2, "$$$$$$$", $c1
.db $c2, $c3, $c4, $c5, "$$$$$$$$", $e3, $24, $24
.db $d6, $db, $df, $de, $db, $ee, $24, $24
.db $e3, $24, $c6, $c7, $c8, $c8, $c8, $24
.db $c9, $ca, $cb, $cc, $cd, $c8, $c8, $c8
.db $c8, $e8, $e9, $d3, $24, $e2, $24, $24
.db $d6, $db, $db, $dc, $db, $d7, $24, $24
.db $e2, "$$$$$$$$$", $ce, $cf, "$$$$$", $ea, $eb, $ec
.db $24, $e3, $24, $24, $d6, $db, $df, $dc
.db $db, $d7, $24, $24, $e3, "$$$$$$$$$", $d1, $d2
.db "$$$$$$$$$", $e2, $24, $24, $d6, $db, $db
Label_c461:
.db $dc, $d8, $e1, $d5, $24, $e6, $e4, $e5
.db $e4, $e5, $e4, $e5, $e4, $e5, $e4, $e5
.db $e4, $e5, $e4, $e5, $e4, $e5, $e4, $e5
.db $e4, $e5, $e6, $24, $d4, $e1, $d9, $dd
.db $dc, $da, $dc, $d7, "$$$$$$$$$", $f0, $01, $09
.db $08, $06, $24, $17, $12, $17, $1d, $0e
.db $17, $0d, $18, $24, $d6, $dc, $db, $df
.db $dc, $da, $dc, $ee, "$$$$$$$$$$$$$$$$$$$$$$$$", $d6, $de, $ed
.db $dd, $dc, $da, $de, $d7, "$$$$$$$$$$$$$$$$$$$$$$$$", $d6, $de
.db $db, $dd, $e1, $d9, $dc, $ed, $e0, $ef
.db $24, $24, $19, $1e, $1c, $11, $24, $1c
.db $1d, $0a, $1b, $1d, $24, $0b, $1e, $1d
.db $1d, $18, $17, $24, $24, $24, $d6, $d8
.db $e1, $d9, $dd, $ed, $de, $d8, $e1, $e1
.db $d5, "$$$$$$$$$$$$$$$$$$$$$", $d6, $da, $dd, $ed, $dd, $db
.db $de, $da, $dc, $dd, $d8, $e0, $e0, $ef
.db $24, $24, $24, $24, $d4, $e0, $e0, $d5
.db "$$$$$$$$", $d4, $ef, $da, $da, $df, $db, $df
.db $db, $dc, $da, $de, $df, $da, $dc, $dd
.db $db, $26, $26, $26, $26, $da, $dc, $dd
.db $ed, $e0, $e0, $ef, $24, $d4, $e0, $e0
.db $e0, $d9, $db, $da, $da, $df, $db
Label_c561:
.db $ed, $d8, $e1, $d9, $de, $d8, $e1, $d9
.db $df, $db, $26, $26, $26, $26, $da, $dc
.db $d8, $e1, $d9, $dc, $d8, $e0, $d9, $dc
.db $dd, $dd, $d8, $e1, $e1, $d9, $dd, $ed
.db $ed, $da, $dd, $ed, $de, $da, $dc, $db
.db $dd, $db, $26, $26, $26, $26, $da, $de
.db $da, $dc, $db, $de, $da, $dd, $ed, $dc
.db $dc, $dd, $da, $dc, $dc, $db, $dd, $ed
.db $ed, $da, $dd, $d8, $e1, $da, $dc, $db
.db $df, $db, $26, $26, $26, $26, $da, $d8
.db $d9, $dc, $db, $dc, $da, $d8, $e1, $d9
.db $de, $df, $da, $d8, $e1, $e1, $d9, $e1
.db $ed, $d9, $df, $da, $dc, $da, $de, $db
.db $dd, $db, $26, $26, $26, $26, $da, $da
.db $ed, $de, $d8, $e1, $e1, $d9, $dc, $db
.db $de, $d8, $e1, $d9, $dd, $dd, $db, $dc
.db $df, $db, $df, $da, $dc, $db, $de, $db
.db $dd, $db, $26, $26, $26, $26, $da, $da
.db $db, $dd, $da, $de, $d8, $e1, $d9, $db
.db $de, $da, $dd, $db, $de, $df, $d8, $e1
.db $df, $db, $df, $da, $dc, $db, $de, $db
.db $dd, $db, $26, $26, $26, $26, $da, $da
.db $db, $dd, $da, $de, $da, $dd, $db, $db
.db $de, $da, $dd, $db, $de, $df, $dc, $e1
NMI_Routine:
LDX #$00
STX $2005
STX $2005
RTI
IRQ_Routine:
RTI
.org $fffa, $00
.dw NMI_Routine
.dw Reset_Routine
.dw IRQ_Routine
Looking at this disassembly, several things come to mind:
- Our ASCII detection did a good job with that string at the beginning. Nice.
- This code introduces only a few new instructions. It won't be too cumbersome to add code gen to support this.
- It looks like the disassembler was able to disassemble the entire program. You can see at the end there is an infinite loop and then data follows.
- ASCII detection found some false positives. Oh well. It makes no difference to the execution of the program.
- The IRQ interrupt is not used, but it looks like the NMI interrupt might be used.
Let's see if we can once again delay dealing with interrupts at all.
Modify the NMI_Routine block so that it looks like this:
NMI_Routine:
RTI
Good thing we bothered to make an assembler. Now we can put the ROM back together, run it in an emulator, and see if it still works:
$ ./jamulate -rom roms/Zelda/Zelda.jam building rom from roms/Zelda/Zelda.jam saving rom Zelda.NES
Again, writing the code to pack the rom back together into an .nes file is left as an exercise to the reader.
Now we observe the ROM running in an emulator and see if it still works:
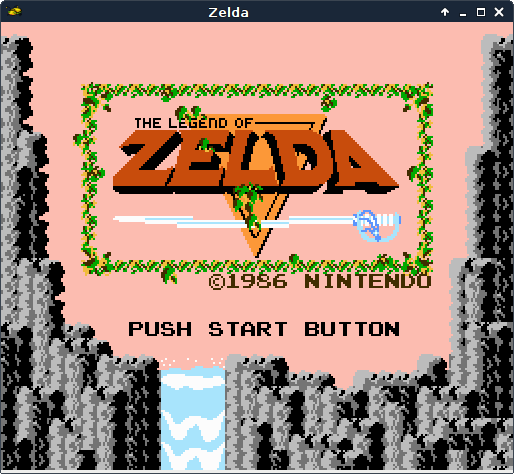
Ha! It works but the sword is bent. That's actually pretty convenient - now when we want to make interrupts work, we know how to test them. But like true software developers, we're going to ignore any and all problems as long as possible.
The only thing left to do then, is to add code gen support for the new instructions. This leads us to our first challenge.
Challenge: Runtime Address Checks
Looking at the disassembled code for Zelda Title Screen Simulator, there is one instruction that stands out as a bit more tricky to recompile than the others:
STA ($00), Y
This is an indirect instruction. It tells the CPU to:
- Interpret the values in $0000 and $0001 as a memory address.
- Add the value of register Y to the address to compute a new address.
- Store the value of register A to the new address.
Quite a useful instruction, but it poses a challenge for recompilation. Because values in memory addresses $0000 and $0001 could be anything, only at runtime will we learn which memory address is about to be updated.
Recall that the NES uses memory mapped I/O. This means that this instruction could be saving a value in memory, but it could also be talking to the PPU, the APU, the game pad controller, or even a mapper. Since this one instruction could be doing any of these things depending on runtime state, we will have to add a runtime address check.
Here's what the code generation looks like for STA-indirect-Y:
func (i *Instruction) Compile(c *Compilation) {
switch i.OpCode {
// ... more cases for other indirect instructions
case 0x91: // sta indirect y
// load the base address at the address indicated by the instruction
baseAddr := c.loadWord(i.Value)
// load the 8-bit value of register Y
rY := c.builder.CreateLoad(c.rY, "")
// zero extend the 8-bit value of Y to 16 bits
// so that we can add it to baseAddr
rYw := c.builder.CreateZExt(rY, llvm.Int16Type(), "")
// compute the pointer to the address to store a byte
addr := c.builder.CreateAdd(baseAddr, rYw, "")
// load the value of register A
rA := c.builder.CreateLoad(c.rA, "")
// call dynStore with our computed address and value of A.
// dynStore will figure out what to do with the value and address.
c.dynStore(addr, rA)
}
}
func (c *Compilation) loadWord(addr int) llvm.Value {
// Load a little endian word.
// Load the low byte.
ptrByte1 := c.load(addr)
// Load the high byte.
ptrByte2 := c.load(addr + 1)
// Zero extend the 8-bit values to 16-bit.
ptrByte1w := c.builder.CreateZExt(ptrByte1, llvm.Int16Type(), "")
ptrByte2w := c.builder.CreateZExt(ptrByte2, llvm.Int16Type(), "")
// Shift the high byte left by 8.
shiftAmt := llvm.ConstInt(llvm.Int16Type(), 8, false)
word := c.builder.CreateShl(ptrByte2w, shiftAmt, "")
// Bitwise OR the high and low bytes together and return that.
return c.builder.CreateOr(word, ptrByte1w, "")
}
func (c *Compilation) load(addr int) llvm.Value {
// This function is used to load a byte from an address that we know
// at compile-time.
switch {
default:
c.Errors = append(c.Errors, fmt.Sprintf("reading from $%04x not implemented", addr))
return llvm.ConstNull(llvm.Int8Type())
case 0x0000 <= addr && addr < 0x2000:
// 2KB working RAM. mask because mirrored
maskedAddr := addr & (0x800 - 1)
indexes := []llvm.Value{
llvm.ConstInt(llvm.Int16Type(), 0, false),
llvm.ConstInt(llvm.Int16Type(), uint64(maskedAddr), false),
}
ptr := c.builder.CreateGEP(c.wram, indexes, "")
v := c.builder.CreateLoad(ptr, "")
return v
case 0x2000 <= addr && addr < 0x4000:
// PPU registers. mask because mirrored
switch addr & (0x8 - 1) {
case 2:
return c.builder.CreateCall(c.ppuReadStatusFn, []llvm.Value{}, "")
case 4:
return c.builder.CreateCall(c.ppuReadOamDataFn, []llvm.Value{}, "")
case 7:
return c.builder.CreateCall(c.ppuReadDataFn, []llvm.Value{}, "")
default:
c.Errors = append(c.Errors, fmt.Sprintf("reading from $%04x not implemented", addr))
return llvm.ConstNull(llvm.Int8Type())
}
// ... There are more cases to handle; here we only include WRAM and the PPU.
}
panic("unreachable")
}
func (c *Compilation) dynStore(addr llvm.Value, val llvm.Value) {
// runtime memory check
storeDoneBlock := c.createBlock("StoreDone")
x2000 := llvm.ConstInt(llvm.Int16Type(), 0x2000, false)
inWRam := c.builder.CreateICmp(llvm.IntULT, addr, x2000, "")
notInWRamBlock := c.createIf(inWRam)
// this generated code runs if the write is happening in the WRAM range
maskedAddr := c.builder.CreateAnd(addr, llvm.ConstInt(llvm.Int16Type(), 0x800-1, false), "")
indexes := []llvm.Value{
llvm.ConstInt(llvm.Int16Type(), 0, false),
maskedAddr,
}
ptr := c.builder.CreateGEP(c.wram, indexes, "")
c.builder.CreateStore(val, ptr)
c.builder.CreateBr(storeDoneBlock)
// this generated code runs if the write is > WRAM range
c.selectBlock(notInWRamBlock)
x4000 := llvm.ConstInt(llvm.Int16Type(), 0x4000, false)
inPpuRam := c.builder.CreateICmp(llvm.IntULT, addr, x4000, "")
notInPpuRamBlock := c.createIf(inPpuRam)
// this generated code runs if the write is in the PPU RAM range
maskedAddr = c.builder.CreateAnd(addr, llvm.ConstInt(llvm.Int16Type(), 0x8-1, false), "")
badPpuAddrBlock := c.createBlock("BadPPUAddr")
sw := c.builder.CreateSwitch(maskedAddr, badPpuAddrBlock, 7)
// this generated code runs if the write is in a bad PPU RAM addr
c.selectBlock(badPpuAddrBlock)
c.createPanic("invalid store address: $%04x\n", []llvm.Value{addr})
ppuCtrlBlock := c.createBlock("ppuctrl")
sw.AddCase(llvm.ConstInt(llvm.Int16Type(), 0, false), ppuCtrlBlock)
c.selectBlock(ppuCtrlBlock)
c.builder.CreateCall(c.ppuCtrlFn, []llvm.Value{val}, "")
c.builder.CreateBr(storeDoneBlock)
ppuMaskBlock := c.createBlock("ppumask")
sw.AddCase(llvm.ConstInt(llvm.Int16Type(), 1, false), ppuMaskBlock)
c.selectBlock(ppuMaskBlock)
c.builder.CreateCall(c.ppuMaskFn, []llvm.Value{val}, "")
c.builder.CreateBr(storeDoneBlock)
oamAddrBlock := c.createBlock("oamaddr")
sw.AddCase(llvm.ConstInt(llvm.Int16Type(), 3, false), oamAddrBlock)
c.selectBlock(oamAddrBlock)
c.builder.CreateCall(c.oamAddrFn, []llvm.Value{val}, "")
c.builder.CreateBr(storeDoneBlock)
oamDataBlock := c.createBlock("oamdata")
sw.AddCase(llvm.ConstInt(llvm.Int16Type(), 4, false), oamDataBlock)
c.selectBlock(oamDataBlock)
c.builder.CreateCall(c.setOamDataFn, []llvm.Value{val}, "")
c.builder.CreateBr(storeDoneBlock)
ppuScrollBlock := c.createBlock("ppuscroll")
sw.AddCase(llvm.ConstInt(llvm.Int16Type(), 5, false), ppuScrollBlock)
c.selectBlock(ppuScrollBlock)
c.builder.CreateCall(c.setPpuScrollFn, []llvm.Value{val}, "")
c.builder.CreateBr(storeDoneBlock)
ppuAddrBlock := c.createBlock("ppuaddr")
sw.AddCase(llvm.ConstInt(llvm.Int16Type(), 6, false), ppuAddrBlock)
c.selectBlock(ppuAddrBlock)
c.builder.CreateCall(c.ppuAddrFn, []llvm.Value{val}, "")
c.builder.CreateBr(storeDoneBlock)
ppuDataBlock := c.createBlock("ppudata")
sw.AddCase(llvm.ConstInt(llvm.Int16Type(), 7, false), ppuDataBlock)
c.selectBlock(ppuDataBlock)
c.builder.CreateCall(c.setPpuDataFn, []llvm.Value{val}, "")
c.builder.CreateBr(storeDoneBlock)
// this generated code runs if the write is >= 0x4000
// There are more cases to handle; here we only show
// handling WRAM and the PPU.
c.selectBlock(notInPpuRamBlock)
c.createPanic()
// done. X_X
c.selectBlock(storeDoneBlock)
}
func (c *Compilation) createIf(cond llvm.Value) llvm.BasicBlock {
// Create a conditional branch along with the 2 target blocks.
// Returns the else block and set the current block to the then block.
elseBlock := c.createBlock("else")
thenBlock := c.createBlock("then")
c.builder.CreateCondBr(cond, thenBlock, elseBlock)
c.selectBlock(thenBlock)
return elseBlock
}
func (c *Compilation) createBlock(name string) llvm.BasicBlock {
bb := llvm.InsertBasicBlock(*c.currentBlock, name)
bb.MoveAfter(*c.currentBlock)
return bb
}
func (c *Compilation) selectBlock(bb llvm.BasicBlock) {
c.builder.SetInsertPointAtEnd(bb)
c.currentBlock = &bb
}
func (c *Compilation) createPanic() {
bytePointerType := llvm.PointerType(llvm.Int8Type(), 0)
ptr := c.builder.CreatePointerCast(c.runtimePanicMsg, bytePointerType, "")
c.builder.CreateCall(c.putsFn, []llvm.Value{ptr}, "")
exitCode := llvm.ConstInt(llvm.Int32Type(), 1, false)
c.builder.CreateCall(c.exitFn, []llvm.Value{exitCode}, "")
c.builder.CreateUnreachable()
}
Let's take a look at what the IR code might look like for this instruction. First, a simplified assembly source file:
.org $c000
Reset_Routine:
STA ($00), Y
STA $2009 ; exit
NMI_Routine:
RTI
IRQ_Routine:
RTI
.org $fffa
.dw NMI_Routine
.dw Reset_Routine
.dw IRQ_Routine
And then the LLVM module that would be generated, before optimizations:
; ModuleID = 'asm_module'
@wram = private global [2048 x i8] zeroinitializer
@panicMsg = private global [51 x i8] c"panic: attempted to write to invalid memory address"
declare i32 @putchar(i32)
declare i32 @puts(i8*)
declare void @exit(i32) noreturn nounwind
declare i8 @rom_ppu_read_status()
declare void @rom_ppu_write_control(i8)
declare void @rom_ppu_write_mask(i8)
declare void @rom_ppu_write_address(i8)
declare void @rom_ppu_write_data(i8)
declare void @rom_ppu_write_oamaddress(i8)
declare void @rom_ppu_write_oamdata(i8)
declare void @rom_ppu_write_scroll(i8)
define i32 @main() {
Entry:
%X = alloca i8
%Y = alloca i8
%A = alloca i8
%SP = alloca i8
%S_neg = alloca i1
%S_zero = alloca i1
%S_dec = alloca i1
%S_int = alloca i1
br label %Reset_Routine
Reset_Routine: ; preds = %Entry
%0 = load i8* getelementptr inbounds ([2048 x i8]* @wram, i8 0, i8 0)
%1 = load i8* getelementptr inbounds ([2048 x i8]* @wram, i8 0, i8 1)
%2 = zext i8 %0 to i16
%3 = zext i8 %1 to i16
%4 = shl i16 %3, 8
%5 = or i16 %4, %2
%6 = load i8* %Y
%7 = zext i8 %6 to i16
%8 = add i16 %5, %7
%9 = load i8* %A
%10 = icmp ult i16 %8, 8192
br i1 %10, label %then, label %else
then: ; preds = %Reset_Routine
%11 = and i16 %8, 2047
%12 = getelementptr [2048 x i8]* @wram, i16 0, i16 %11
store i8 %9, i8* %12
br label %STA_done
else: ; preds = %Reset_Routine
%13 = icmp ult i16 %8, 16384
br i1 %13, label %then2, label %else1
then2: ; preds = %else
%14 = and i16 %8, 7
switch i16 %14, label %BadPPUAddr [
i16 0, label %ppuctrl
i16 1, label %ppumask
i16 3, label %oamaddr
i16 4, label %oamdata
i16 5, label %ppuscroll
i16 6, label %ppuaddr
i16 7, label %ppudata
]
BadPPUAddr: ; preds = %then2
%15 = call i32 @puts(i8* getelementptr inbounds ([51 x i8]* @panicMsg, i32 0, i32 0))
call void @exit(i32 1)
unreachable
ppuctrl: ; preds = %then2
call void @rom_ppu_write_control(i8 %9)
br label %STA_done
ppumask: ; preds = %then2
call void @rom_ppu_write_mask(i8 %9)
br label %STA_done
oamaddr: ; preds = %then2
call void @rom_ppu_write_oamaddress(i8 %9)
br label %STA_done
oamdata: ; preds = %then2
call void @rom_ppu_write_oamdata(i8 %9)
br label %STA_done
ppuscroll: ; preds = %then2
call void @rom_ppu_write_scroll(i8 %9)
br label %STA_done
ppuaddr: ; preds = %then2
call void @rom_ppu_write_address(i8 %9)
br label %STA_done
ppudata: ; preds = %then2
call void @rom_ppu_write_data(i8 %9)
br label %STA_done
else1: ; preds = %else
%16 = call i32 @puts(i8* getelementptr inbounds ([51 x i8]* @panicMsg, i32 0, i32 0))
call void @exit(i32 1)
unreachable
STA_done: ; preds = %ppudata, %ppuaddr, %ppuscroll, %oamdata, %oamaddr, %ppumask, %ppuctrl, %then
%17 = load i8* %A
%18 = zext i8 %17 to i32
call void @exit(i32 %18)
br label %NMI_Routine
NMI_Routine: ; preds = %STA_done
unreachable
IRQ_Routine: ; No predecessors!
unreachable
}
With this framework in place, we can recompile instructions that store to memory addresses only known at runtime. Code generation for the other instructions in this assembly program is straightforward at this point.
So now we can generate a new, native program to run. But how do we get the video to actually display on the screen?
This question brings us to the next challenge.
Challenge: Parallel Systems Running Simultaneously
To find out how to get something rendering on the screen, I looked at Fergulator - an already-working NES emulator written in Go.
Fergulator correctly emulates Super Mario Brothers 1 as well as Zelda Title Screen Simulator, so it will certainly work for our purpose - understanding how the video gets onto the screen.
The answer is easy to find in this well factored codebase.
Looking at the main loop in machine.go, the core
logic is revealed:
cycles = cpu.Step()
for i := 0; i < 3*cycles; i++ {
ppu.Step()
}
for i := 0; i < cycles; i++ {
apu.Step()
}
The CPU runs one instruction and returns how many cycles the instruction took to run, and then the PPU is stepped for 3 times as many cycles, and the APU is stepped the same number of cycles as the CPU.
A problem presents itself here. Our recompiled code replaces the CPU stepping, but we still have the PPU and the APU code to reckon with. We can start by eliminating audio from the equation and dealing with sound later. But no matter how you spin it, the fact remains that the PPU and the CPU run independently of one another, and at differing speeds.
You can choose to recompile program code and run that as the main loop, but then after every instruction you must emulate the PPU for 3 times as many cycles as the instruction took. Or you can choose to run the PPU as the main loop, but then after the appropriate amount of cycles you must emulate the CPU for one instruction.
One of the systems must be emulated.
This is how I solved the problem:
-
Have code generation call
rom_cycle, an external function, after every instruction completes, passing the number of cycles the instruction took as a parameter. -
Bundle in a runtime with the generated executable which implements
rom_cycleand emulates the PPU for the appropriate amount of steps.
It is a shame that we have to do some amount of emulation in this project, where the goal is to statically recompile as much as possible. The solution to this challenge represents a slight compromise to the project's integrity. Yet we press on.
Given this solution, I ported the PPU code as well as the
SDL
and
OpenGL
front-end code from Fergulator to a
small C runtime,
which is compiled with clang.
Here is a snippet explaining the rom_cycle and
main functions:
#include "rom.h"
#include "assert.h"
#include "ppu.h"
#include "SDL/SDL.h"
#include "GL/glew.h"
Ppu* p;
// This function is called by the generated module after every instruction.
void rom_cycle(uint8_t cycles) {
// Check the SDL event loop and quit if the Close event occurs.
flush_events();
// Step the PPU for 3 times number of cycles that just finished.
for (int i = 0; i < 3 * cycles; ++i) {
Ppu_step(p);
}
}
// This function is our new main entry point. We rename the
// main rom entry point to `rom_start` so that we can call it
// from this function.
int main(int argc, char* argv[]) {
// Create a new instance of the PPU emulator core.
p = Ppu_new();
// The PPU code will call `render` when there is a frame ready to display
// on the screen. The `render` function performs the SDL and OpenGL
// calls to render the frame to the window.
p->render = &render;
// Remember that in the generated rom module, we export the ROM mirroring
// setting after reading it from the .nes file. Here we use it to configure
// the nametable code.
Nametable_setMirroring(&p->nametables, rom_mirroring);
// We currently only support ROMs with 1 CHR bank.
assert(rom_chr_bank_count == 1);
// In the generated rom module, we have the CHR ROM data in memory, as well
// as `rom_read_chr`, an exported function which will copy the data to a
// pointer. We use that to initialize the video RAM.
rom_read_chr(p->vram);
// This does the SDL and OpenGL setup such as creating the display window.
init_video();
// Here we call into the main entry point to the recompiled ROM code.
rom_start();
// Free up memory associated with the PPU emulator instance.
Ppu_dispose(p);
}
uint8_t rom_ppu_read_status() {
return Ppu_readStatus(p);
}
void rom_ppu_write_control(uint8_t b) {
Ppu_writeControl(p, b);
}
void rom_ppu_write_mask(uint8_t b) {
Ppu_writeMask(p, b);
}
void rom_ppu_write_oamaddress(uint8_t b) {
Ppu_writeOamAddress(p, b);
}
void rom_ppu_write_address(uint8_t b) {
Ppu_writeAddress(p, b);
}
void rom_ppu_write_data(uint8_t b) {
Ppu_writeData(p, b);
}
void rom_ppu_write_oamdata(uint8_t b) {
Ppu_writeOamData(p, b);
}
void rom_ppu_write_scroll(uint8_t b) {
Ppu_writeScroll(p, b);
}
Notice that we include rom.h. This is a header file that defines the contract
that the generated rom module will fulfill:
#include "stdint.h"
enum {
ROM_MIRRORING_VERTICAL,
ROM_MIRRORING_HORIZONTAL,
ROM_MIRRORING_SINGLE_UPPER,
ROM_MIRRORING_SINGLE_LOWER,
};
uint8_t rom_mirroring;
uint8_t rom_chr_bank_count;
// write the chr rom into dest
void rom_read_chr(uint8_t* dest);
// starts executing the PRG ROM.
// this function returns when the the program exits.
void rom_start();
// called after every instruction with the number of
// cpu cycles that have passed.
void rom_cycle(uint8_t);
// PPU hooks
uint8_t rom_ppu_read_status();
void rom_ppu_write_control(uint8_t);
void rom_ppu_write_mask(uint8_t);
void rom_ppu_write_oamaddress(uint8_t);
void rom_ppu_write_oamdata(uint8_t);
void rom_ppu_write_scroll(uint8_t);
void rom_ppu_write_address(uint8_t);
void rom_ppu_write_data(uint8_t);
When we build the final executable file, we can link against this runtime to get a fully operational executable with a video display.
After adding runtime compilation instructions, make does this:
$ make go tool yacc -o jamulator/y.go -v /dev/null jamulator/asm6502.y /home/andy/gocode/bin/nex -e jamulator/asm6502.nex clang -o runtime/main.o -c runtime/main.c clang -o runtime/ppu.o -c runtime/ppu.c clang -o runtime/nametable.o -c runtime/nametable.c ar rcs runtime/runtime.a runtime/main.o runtime/ppu.o runtime/nametable.o go build -o jamulate main.go $
Next we can implement a command which will read a .nes ROM file and perform the recompilation process:
$ ./jamulate -recompile roms/Zelda.NES loading roms/Zelda.NES Disassembling... Decompiling to /tmp/302858262/prg.bc... llc -o /tmp/302858262/prg.o -filetype=obj /tmp/302858262/prg.bc gcc /tmp/302858262/prg.o runtime/runtime.a -lGLEW -lGL -lSDL -lSDL_gfx -o roms/Zelda Done: roms/Zelda $ file ./roms/Zelda ./roms/Zelda: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), dynamically linked (uses shared libs), for GNU/Linux 2.6.24, BuildID[sha1]=0xa79ee93a78a4745b60ba9d10a58b209d756e8ffa, not stripped $
And so here we have it: an executable binary that depends on SDL and OpenGL, which supposedly will execute the Zelda Title Screen Simulator when run. Does it work?
Note: There is an obvious discrepancy between the screenshot and the output listed above. All output is real; the difference is that the article is organized, ordered, and simplified for clarity and understanding. I did not necessarily write the code in the same order that it is listed in this article.
So we made a small concession to solve this challenge, and we have a simple demo NES ROM running natively. Next let's see if we can fix the dent in that sword.
Challenge: Handling Interrupts
In NES programming, after any instruction, it is possible that the program counter is yanked away from the next expected instruction and instead sent to a predefined location. This is called an interrupt.
There are 3 kinds of interrupts in NES programming:
- Reset
- Occurs when the user presses the reset button. This is also where the program counter starts when the NES powers on.
- IRQ
-
Stands for Interrupt ReQuest. This interrupt can only be fired
if a game uses a mapper or uses the
BRKinstruction. This request can be enabled and disabled with theCLIandSEIinstructions. - NMI
- Stands for Non-Maskable Interrupt because there are no instructions to enable and disable this interrupt. It occurs when the vertical blank begins.
When an interrupt occurs, the program counter and status register are pushed onto the stack, and the program counter is set to the location defined by the interrupt vector table, as seen in code listings above:
.org $fffa
.dw NMI_Routine
.dw Reset_Routine
.dw IRQ_Routine
When a program has finished processing an interrupt,
it typically executes the RTI instruction
to return control flow back to where it was before
the interrupt occurred.
We don't yet have to deal with handling the reset button
being pressed, mappers, or games which execute the
BRK instruction,
so let's work on solving this
problem for the NMI interrupt only.
The PPU performs the vertical blanking which signals the NMI interrupt, and the PPU emulation code is in the runtime. In order to handle NMI interrupts correctly, we have to be ready to jump to the interrupt routine after every single instruction.
We already call into the runtime by calling rom_cycle after
every instruction. This is where the PPU emulation is performed, which
is where the NMI interrupt is generated.
Given this, a natural solution might be something like this:
-
Have
rom_cyclereturn a value indicating which interrupt, if any, has occurred. - After every instruction, check if an interrupt has occurred, and if so, jump to the interrupt routine. Otherwise, continue.
This solution is rather ugly, however. Branching after every instruction decreases execution speed and executable leanness. Further, it leaves a critical problem unsolved: how to jump back to where the program counter was before the interrupt occurred. The solution I came up with instead feels better, but it comes with a caveat. Here's the idea:
-
Switch the register variables from being allocated on the stack in
rom_start, to global variables in the generated module. -
Update
rom_start, the main entry point, to take a parameter indicating which interrupt vector to execute. -
In the runtime, when
rom_startis called for the first time, pass Reset as the interrupt vector to execute. -
In the generated
rom_startcode, insert code at the beginning of the NMI interrupt routine block to push the program counter and the processor status to the stack. -
In
rom_cycle, if there is no interrupt, return as normal. However, if there is an interrupt, callrom_start, passing the correct interrupt vector to execute. -
Generate a return statement for the
RTIinstruction.
The beauty of this solution is that it uses the real native stack for interrupts, in what is probably the most efficient and elegant way to get the desired behavior.
The caveat is that if the game uses RTI for its side-effects instead
of the usual "return from interrupt" behavior, the executable will unexpectedly exit.
Further, if the game simulates returning from an interrupt without using
RTI, the game will crash due to a stack overflow.
Acknowledging these weaknesses, let's plow ahead until we are forced to solve this problem a different way.
Let's see what it looks like to implement the plan.
Update rom_start to take a parameter indicating which interrupt
vector to execute:
func (p *Program) Compile(filename string) (c *Compilation) {
// ...
mainType := llvm.FunctionType(llvm.VoidType(), []llvm.Type{llvm.Int8Type()}, false)
c.mainFn = llvm.AddFunction(c.mod, "rom_start", mainType)
c.mainFn.SetFunctionCallConv(llvm.CCallConv)
// ...
}
Add a reset vector enum to rom.h:
enum {
ROM_INTERRUPT_NONE,
ROM_INTERRUPT_NMI,
ROM_INTERRUPT_RESET,
ROM_INTERRUPT_IRQ,
};
In the runtime, when rom_start is called for the first time,
pass Reset as the interrupt vector to execute.
Also, in rom_cycle, if there is no interrupt, return as normal.
However, if there is an interrupt, call rom_start, passing
the correct interrupt vector to execute:
int interruptRequested = ROM_INTERRUPT_NONE;
void rom_cycle(uint8_t cycles) {
flush_events();
for (int i = 0; i < 3 * cycles; ++i) {
Ppu_step(p);
}
int req = interruptRequested;
if (req != ROM_INTERRUPT_NONE) {
interruptRequested = ROM_INTERRUPT_NONE;
rom_start(req);
}
}
void vblankInterrupt() {
interruptRequested = ROM_INTERRUPT_NMI;
}
int main(int argc, char* argv[]) {
p = Ppu_new();
p->render = &render;
// The PPU code will call this function when an NMI interrupt occurs.
p->vblankInterrupt = &vblankInterrupt;
Nametable_setMirroring(&p->nametables, rom_mirroring);
assert(rom_chr_bank_count == 1);
rom_read_chr(p->vram);
init_video();
// Start the rom executing at the Reset interrupt routine.
rom_start(ROM_INTERRUPT_RESET);
Ppu_dispose(p);
}
In the generated rom_start code, insert code at the beginning
of the NMI interrupt routine block to push the program counter and the
processor status to the stack:
func (c *Compilation) addNmiInterruptCode() {
c.builder.SetInsertPointBefore(c.nmiBlock.FirstInstruction())
// * push PC high onto stack
// * push PC low onto stack
c.pushWordToStack(c.builder.CreateLoad(c.rPC, ""))
// * push processor status onto stack
c.pushToStack(c.getStatusByte())
}
func (c *Compilation) pushWordToStack(word llvm.Value) {
high16 := c.builder.CreateLShr(word, llvm.ConstInt(llvm.Int16Type(), 8, false), "")
high := c.builder.CreateTrunc(high16, llvm.Int8Type(), "")
c.pushToStack(high)
low16 := c.builder.CreateAnd(word, llvm.ConstInt(llvm.Int16Type(), 0xff, false), "")
low := c.builder.CreateTrunc(low16, llvm.Int8Type(), "")
c.pushToStack(low)
}
func (c *Compilation) pushToStack(v llvm.Value) {
// write the value to the address at current stack pointer
sp := c.builder.CreateLoad(c.rSP, "")
spZExt := c.builder.CreateZExt(sp, llvm.Int16Type(), "")
addr := c.builder.CreateAdd(spZExt, llvm.ConstInt(llvm.Int16Type(), 0x100, false), "")
c.dynStore(addr, v)
// stack pointer = stack pointer - 1
spMinusOne := c.builder.CreateSub(sp, llvm.ConstInt(llvm.Int8Type(), 1, false), "")
c.builder.CreateStore(spMinusOne, c.rSP)
}
func (c *Compilation) getStatusByte() llvm.Value {
// zextend
s7z := c.builder.CreateZExt(c.builder.CreateLoad(c.rSNeg, ""), llvm.Int8Type(), "")
s6z := c.builder.CreateZExt(c.builder.CreateLoad(c.rSOver, ""), llvm.Int8Type(), "")
s4z := c.builder.CreateZExt(c.builder.CreateLoad(c.rSBrk, ""), llvm.Int8Type(), "")
s3z := c.builder.CreateZExt(c.builder.CreateLoad(c.rSDec, ""), llvm.Int8Type(), "")
s2z := c.builder.CreateZExt(c.builder.CreateLoad(c.rSInt, ""), llvm.Int8Type(), "")
s1z := c.builder.CreateZExt(c.builder.CreateLoad(c.rSZero, ""), llvm.Int8Type(), "")
s0z := c.builder.CreateZExt(c.builder.CreateLoad(c.rSCarry, ""), llvm.Int8Type(), "")
// shift
s7z = c.builder.CreateShl(s7z, llvm.ConstInt(llvm.Int8Type(), 7, false), "")
s6z = c.builder.CreateShl(s6z, llvm.ConstInt(llvm.Int8Type(), 6, false), "")
s4z = c.builder.CreateShl(s4z, llvm.ConstInt(llvm.Int8Type(), 4, false), "")
s3z = c.builder.CreateShl(s3z, llvm.ConstInt(llvm.Int8Type(), 3, false), "")
s2z = c.builder.CreateShl(s2z, llvm.ConstInt(llvm.Int8Type(), 2, false), "")
s1z = c.builder.CreateShl(s1z, llvm.ConstInt(llvm.Int8Type(), 1, false), "")
// or
s0z = c.builder.CreateOr(s0z, s1z, "")
s0z = c.builder.CreateOr(s0z, s2z, "")
s0z = c.builder.CreateOr(s0z, s3z, "")
s0z = c.builder.CreateOr(s0z, s4z, "")
s0z = c.builder.CreateOr(s0z, s6z, "")
s0z = c.builder.CreateOr(s0z, s7z, "")
return s0z
}
Generate a return statement for the RTI instruction:
func (i *Instruction) Compile(c *Compilation) {
switch i.OpCode {
// ... other cases
case 0x40: // RTI implied
// Restore the old status register values from the stack.
c.pullStatusReg()
// We get the PC from the stack, but since we rely on the native
// stack, we trash the value.
_ = c.pullWordFromStack()
// This will call the `rom_cycle` function. RTI always takes
// 6 cycles.
c.cycle(6)
// Generate a return statement.
c.builder.CreateRetVoid()
// So that when another block is encountered, we do not
// create an unconditional branch to it.
c.currentBlock = nil
// ... other cases
}
}
func (c *Compilation) cycle(count int) {
v := llvm.ConstInt(llvm.Int8Type(), uint64(count), false)
c.builder.CreateCall(c.cycleFn, []llvm.Value{v}, "")
}
And so here we have it: an elegant but imperfect solution to the interrupt problem. Let's see if it fixes the bent sword:
Looks like progress to me! At this point the project can recompile a small, simple title screen demo NES program. The real challenge awaits: can it be made to work for a real NES game?
There are many games to choose from. Ideally we would pick one that poses fewer additional challenges. One filter we can apply is to eliminate games that use mappers, since we have hitherto ignored mapper support entirely.
This limits the choices significantly. The only games worth noting that do not use a mapper are:
Of these, there is an obvious answer to which game we should support first, which, of course, is Super Mario Brothers 1.
Our next challenge is revealed when we crack open the disassembly for SMB.
Challenge: Detecting a Jump Table
Here's a small section of Super Mario Brothers 1 disassembly:
Label_8212:
LDA $0770
JSR Label_8e04
AND ($82), Y
.db $dc, $ae, $8b, $83, $18, $92
Notice anything peculiar?
After the value at $0770 is loaded into register A, and we return
from the Label_8e04 subroutine,
there is an uncommon indirect AND instruction,
followed by data.
What could possibly be happening here?
Super Mario Brothers 1 is using a common assembly programming technique
called a dynamic jump table.
Take a look at the Label_8e04 subroutine:
Label_8e04:
ASL
TAY
PLA
STA $04
PLA
STA $05
INY
LDA ($04), Y
STA $06
INY
LDA ($04), Y
STA $07
JMP ($0006)
Notice that although this label is jumped to with JSR,
it never uses the RTS instruction.
Let's break it down further into readable pseudocode:
; Dynamic Jump Table. Call this label with JSR
; so that the old PC is on the stack.
; Immediately following the JSR statement should be
; .dw statements indicating the labels to jump to
; depending on the value of register A.
Label_8e04:
; Register A holds the index of the label that we wish to jump to.
; Multiply A by 2 because each table entry is 2 bytes.
ASL ; A = A * 2
; The useful indirect instructions use Y as the index, and we need
; to repurpose A.
TAY ; Y = A
; Since this label was called with JSR, the old PC is on the top
; of the stack. Here we get the lower byte since this is a little
; endian system.
PLA ; A = Stack.Pop()
; Save the lower byte of the old PC into memory.
STA $04 ; Memory[$04] = A
; Get the higher byte of the old PC off the stack.
PLA ; A = Stack.Pop()
; Save the higher byte of the old PC into memory.
STA $05 ; Memory[$05] = A
; JSR pushes the address - 1 of the next instruction to the stack.
; So we add 1 to Y to get the index of the first byte of the jump
; destination.
INY ; Y = Y + 1
; Get the first byte of the jump destination.
LDA ($04), Y ; A = Memory[Memory[$04] + Y]
; Save the first byte of the jump destination.
STA $06 ; Memory[$06] = A
; Increment Y to get the index of the 2nd byte of the jump destination.
INY ; Y = Y + 1
; Get the 2nd byte of the jump instruction.
LDA ($04), Y ; A = Memory[Memory[$04] + Y]
; Save the 2nd byte of the jump instruction.
STA $07 ; Memory[$07] = A
; Jump to the location that was just constructed.
JMP ($0006) ; Jump to address at $0006 - $0007
If we know that Label_8e04 is a jump table, we can
mark the bytes following the JSR as .dw
labels which enables us to further disassemble the program.
The disassembled snippet from earlier would look like this:
Label_8212:
LDA $0770
JSR Label_8e04
.dw Label_8231
.dw Label_aedc
.dw Label_838b
.dw Label_9218
Without this jump table detection, the bytes at each of those labels
remain .db statements, unable to be decoded.
This is problematic because our strategy currently
depends on all instructions being completely disassembled so that
they can be decompiled and recompiled.
This is not a mere corner-case either. This technique is repeated in many games, including Super Mario Brothers 3 and Pac-Man.
Fortunately, it is straightforward to identify and process a jump table like this without changing too much code. I solved it with a state machine - essentially pattern-matching or a regular expression for instructions:
func (d *Disassembly) detectJumpTable(addr int) bool {
const (
expectAsl = iota
expectTay
expectPlaA
expectStaA
expectPlaB
expectStaB
expectInyC
expectLdaC
expectStaC
expectInYD
expectLdaD
expectStaD
expectJmp
)
state := expectAsl
var memA, memC int
for elem := d.prog.elemAtAddr(addr); elem != nil; elem = elem.Next() {
switch state {
case expectAsl:
i, ok := elem.Value.(*Instruction)
if !ok {
return false
}
if i.OpCode != 0x0a {
return false
}
state = expectTay
case expectTay:
i, ok := elem.Value.(*Instruction)
if !ok {
return false
}
if i.OpCode != 0xa8 {
return false
}
state = expectPlaA
case expectPlaA:
i, ok := elem.Value.(*Instruction)
if !ok {
return false
}
if i.OpCode != 0x68 {
return false
}
state = expectStaA
case expectStaA:
i, ok := elem.Value.(*Instruction)
if !ok {
return false
}
if i.OpCode != 0x85 && i.OpCode != 0x8d {
return false
}
memA = i.Value
state = expectPlaB
case expectPlaB:
i, ok := elem.Value.(*Instruction)
if !ok {
return false
}
if i.OpCode != 0x68 {
return false
}
state = expectStaB
case expectStaB:
i, ok := elem.Value.(*Instruction)
if !ok {
return false
}
if i.OpCode != 0x85 && i.OpCode != 0x8d {
return false
}
if i.Value != memA+1 {
return false
}
state = expectInyC
case expectInyC:
i, ok := elem.Value.(*Instruction)
if !ok {
return false
}
if i.OpCode != 0xc8 {
return false
}
state = expectLdaC
case expectLdaC:
i, ok := elem.Value.(*Instruction)
if !ok {
return false
}
if i.OpCode != 0xb1 {
return false
}
if i.Value != memA {
return false
}
state = expectStaC
case expectStaC:
i, ok := elem.Value.(*Instruction)
if !ok {
return false
}
if i.OpCode != 0x85 && i.OpCode != 0x8d {
return false
}
memC = i.Value
state = expectInYD
case expectInYD:
i, ok := elem.Value.(*Instruction)
if !ok {
return false
}
if i.OpCode != 0xc8 {
return false
}
state = expectLdaD
case expectLdaD:
i, ok := elem.Value.(*Instruction)
if !ok {
return false
}
if i.OpCode != 0xb1 {
return false
}
if i.Value != memA {
return false
}
state = expectStaD
case expectStaD:
i, ok := elem.Value.(*Instruction)
if !ok {
return false
}
if i.OpCode != 0x85 && i.OpCode != 0x8d {
return false
}
if i.Value != memC+1 {
return false
}
state = expectJmp
case expectJmp:
i, ok := elem.Value.(*Instruction)
if !ok {
return false
}
if i.OpCode != 0x6c {
return false
}
if i.Value != memC {
return false
}
return true
}
}
return false
}
Given this detection function, it is a matter of adding logic to
the JSR disassembly. If a jump table is detected,
mark the following bytes as .dw label statements.
Otherwise, continue marking the next address as an instruction
as usual.
After adding jump table detection, it looks like all the program instructions are disassembled successfully. But there are still some tricks up the assembly programmers' sleeves.
Challenge: Indirect Jumps
We just looked at a dynamic jump table implementation which included this instruction:
JMP ($0006)
This is problematic because we do not know what will be in the memory addresses $0006 and $0007 until the instruction is actually executed.
One solution is to use our own jump table. We can use our knowledge of the address of each label to create a basic block to jump to when an indirect jump is encountered:
func (c *Compilation) addDynJumpTable() {
c.dynJumpBlock = llvm.AddBasicBlock(c.mainFn, "DynJumpTable")
c.builder.SetInsertPointAtEnd(c.dynJumpBlock)
pc := c.builder.CreateLoad(c.rPC, "")
// Here, panic block causes a runtime error and crashes.
sw := c.builder.CreateSwitch(pc, panicBlock, len(c.dynJumpAddrs))
for addr, block := range c.dynJumpAddrs {
addrVal := llvm.ConstInt(llvm.Int16Type(), uint64(addr), false)
sw.AddCase(addrVal, block)
}
}
And when a JMP indirect is encountered:
func (i *Instruction) Compile(c *Compilation) {
switch i.OpCode {
// ... other cases
case 0x6c: // jmp indirect
newPc := c.loadWord(i.Value)
c.builder.CreateStore(newPc, c.rPC)
c.cycle(5)
c.builder.CreateBr(c.dynJumpBlock)
c.currentBlock = nil
// ... other cases
}
}
This ends up looking something like this in the generated module:
DynJumpTable:
%63674 = load i16* @PC
switch i16 %63674, label %PanicBlock [
i16 -11559, label %Label_d2d9
i16 -3527, label %Label_f239
i16 -27243, label %Label_9595
i16 -28888, label %Label_8f28
; (about 2,000 more cases)
i16 -3045, label %Label_f41b
i16 -18147, label %Label_b91d
]
This solution will work as long as the indirect jump chooses to jump to one of the labels. However it causes a runtime crash if the indirect jump sets the PC to anything else. As we will soon find out, assembly programmers not only force the processor to do this, but even more heinous acts.
Challenge: Dirty Assembly Tricks
Super Mario Brothers 1 is an amazing technical feat. Every last byte of the 32KB available program space is utilized. In fact, some bytes are even dual purposed to save space. Have a look at this code from our Super Mario 1 disassembly:
Label_8220:
LDY #$00
.db $2c
Label_8223:
LDY #$04
LDA #$f8
Label_8227:
STA $0200, Y
INY
INY
INY
INY
BNE Label_8227
RTS
Note the .db $2c.
$2c is the op code for BIT absolute, which is 3 bytes - 1 byte op code
and then 2 bytes for the absolute address.
LDY #$04 is 2 bytes - $a0 for the op code and then
$04 for the immediate value.
So how this works is if you jump to Label_8220, it does Y = $00, and then
sabotages the next instruction, causing the Y = $04 to not happen. Instead,
the BIT instruction sets some status bits in a way that does not matter.
Then it picks up the next instruction, LDA #$f8,
as if you had jumped to Label_8223 with a different Y.
This occurs over a dozen times in Super Mario 1. Similarly, there are instances where the program jumps into the middle of an instruction.
Yet another trick is adding an address on the stack and then using the
RTS instruction to jump there, kind of like a homebrew
JMP indirect instruction.
And even with indirect JMP instructions, the programmer
may choose to jump to RAM or somewhere other than a label.
These issues must be resolved if we want a playable game. Sadly, the solution marks the final nail in the coffin of the integrity of this project.
The solution is to embed an interpreter runtime in the generated binary:
- Instead of identifying data that is read and only including that in the generated module, include all the PRG ROM, since we don't know which addresses may be accessed at runtime.
- After every instruction, update the program counter variable.
-
Include a basic block in
rom_startcalledInterpretwhich reads the program counter variable, reads the op code from the PRG ROM, performs the necessary operation, and then jumps to theDynJumpTableblock. -
Update the
DynJumpTableblock so that the default case jumps to theInterpretblock instead of panicking. -
When control flow runs into data, branch to the
Interpretblock.
Here's a diagram to help clarify:

This strategy ensures that NES games will run correctly,
at the cost of efficiency.
Normally, doing something like updating the program counter variable after
every instruction would be optimized away, but this is thwarted by interrupts
in our case.
Because after every instruction we call rom_cycle, which in turn might
call rom_start with an interrupt, all the global variable state must be
correct before we call rom_cycle.
This defeats the entire point of this project.
At this point we might as well emulate.
In fact, with the new Interpret block, we are doing just that.
Although, to be fair, I only had to add emulation support for 6 op codes to get Super Mario Brothers 1 working.
Video: Playing Super Mario Brothers 1 on Native Machine Code
In this video I demonstrate my (poor) Super Mario 1 skills in a recompiled executable. I also demonstrate the movie playback feature that was instrumental in debugging.
Unsolved Challenge: Mappers
At this point in the project we have Super Mario Brothers 1 running mostly on native code, although not very highly optimized. We've learned that static compilation, while possible, is rendered pointless by some of the inherent challenges that emulating a system presents. Thus there is no reason to solve the challenge that mappers provide.
The only thing I will say about mappers here is that they present an additional layer of complexity for static disassembly, and they make it blatantly obvious that Just-In-Time compilation is a better technique than static recompilation. More on that in the conclusion.
Community Support
NES seems to be a common system for first-time emulator programmers. As such, I was happy to find a large swath of documentation online explaining in great detail how the NES works, emulator tutorials, fascinating optimization articles, the invaluable Nesdev wiki, and more. Even so, there is nothing like asking a question and having a knowledgeable person answer in real-time. The folks in #nesdev on EFNet are fun, engaging, working on all kinds of interesting projects, and helpful. Thanks especially to Ulfalizer, sherlock_, Bisqwit, Movax12, and scottferg for answering my questions, even when they seemed stupid. The Nesdev Forums are nice as well.
There were also instances where I asked for some help with Go - how to write good code, what is the best way to implement certain things, etc. #go-nuts on Freenode is great for that. The channel is active - you'll nearly always get an answer immediately.
As for my contributions back to the community, I did help scottferg fix a bug in his emulator, which fixed support for Maniac Mansion.
I also filed an llvm feature request asking for the ability to generate comments in IR code. This would make it much, much easier to debug generated IR code.
Conclusion
After completing this project, I believe that static recompilation does not have a practical application for video game emulation. It is thwarted by the inability to completely disassemble a game without executing it as well as the fact that multiple systems are executing in parallel, possibly causing interrupts in the game code. There is a constant struggle between correctness and optimized code. Nearly all optimizations must be tossed out the window in the interest of correctness. Even more compromises would have to be made to start supporting advanced emulator features such as saving state or rewinding.
A comparison could be made between a console game and an interpreted language such as JavaScript. There are amazingly fast JavaScript interpreters such as V8, but they do not work by statically compiling the script. Instead they use Just-In-Time compilation, along with some advanced techniques, to achieve great speeds. These techniques could be applied to JIT console game compilation.
For example, one such technique is to identify a section of code, make some assumptions based on heuristics which allow for highly optimized native code generation, and then detect if those assumptions are broken. If the assumptions are broken, the generated native code is tossed, and emulation takes over. However, if the assumptions are upheld, the recompiled block of code will execute with blazing fast native speed.
This technique is much more suited to an emulator with a JIT core, rather than trying to do everything statically, especially since the emulator can "notice" at runtime which memory addresses are used as instructions and which memory addresses are used as data.
Furthermore, distributing static executables that function as games would be problematic as far as copyright infringement is concerned. By keeping ROMs separate from the emulator executable, the emulator can be distributed freely and easily without risking trouble.
That being said, I do feel like this project was worthwhile in that it was intellectually stimulating and highly effective at teaching me, and hopefully now, you, how the Nintendo Entertainment System works, how to use LLVM effectively, and an introduction to a wide range of problems that compilers and interpreters face.